1、自定义图标自定义图标有多种方法,比如使用图片、精灵图、CSS 样式绘制、矢量字体、SVG 矢量文件等方法。这里推荐使用矢量字体自定义小程序的 icon 组件图标。
字体类型有两类:点阵字体 和 矢量字体。目前使用最广泛的是 矢量字体。
矢量字体大概分三类:Adobe 的 Type1、Apple 和 Microsoft 主导的 TrueType、Adobe 和 Apple 以及 Microsoft 主导的开源字体 OpenType。在矢量字体里,每一个 Unicode 仅是编码的索引,每个字符描述信息是一个几何矢量绘图描述信息。以 Type1 为例,它使用三次贝塞尔曲线来绘制字形,TrueType 则使用二次贝塞尔曲线描述字形。由于矢量字体是绘制出来的,所以它可以实时填充任何颜色,可以无级缩放而没有锯齿。
阿里巴巴矢量图标库 不仅提供常用图标下载,还提供自定义矢量图标字体的生成与下载。我们可以在这个网站上搜索自己想要的图标,在线编辑,并下载样式文件,然后在小程序里使用。
获取矢量图标
打开 阿里巴巴矢量图标库 ,首页如下:

随意选择一个图标集,比如第一个:
随意选择一个图标加入购物车,比如第一行第四个:
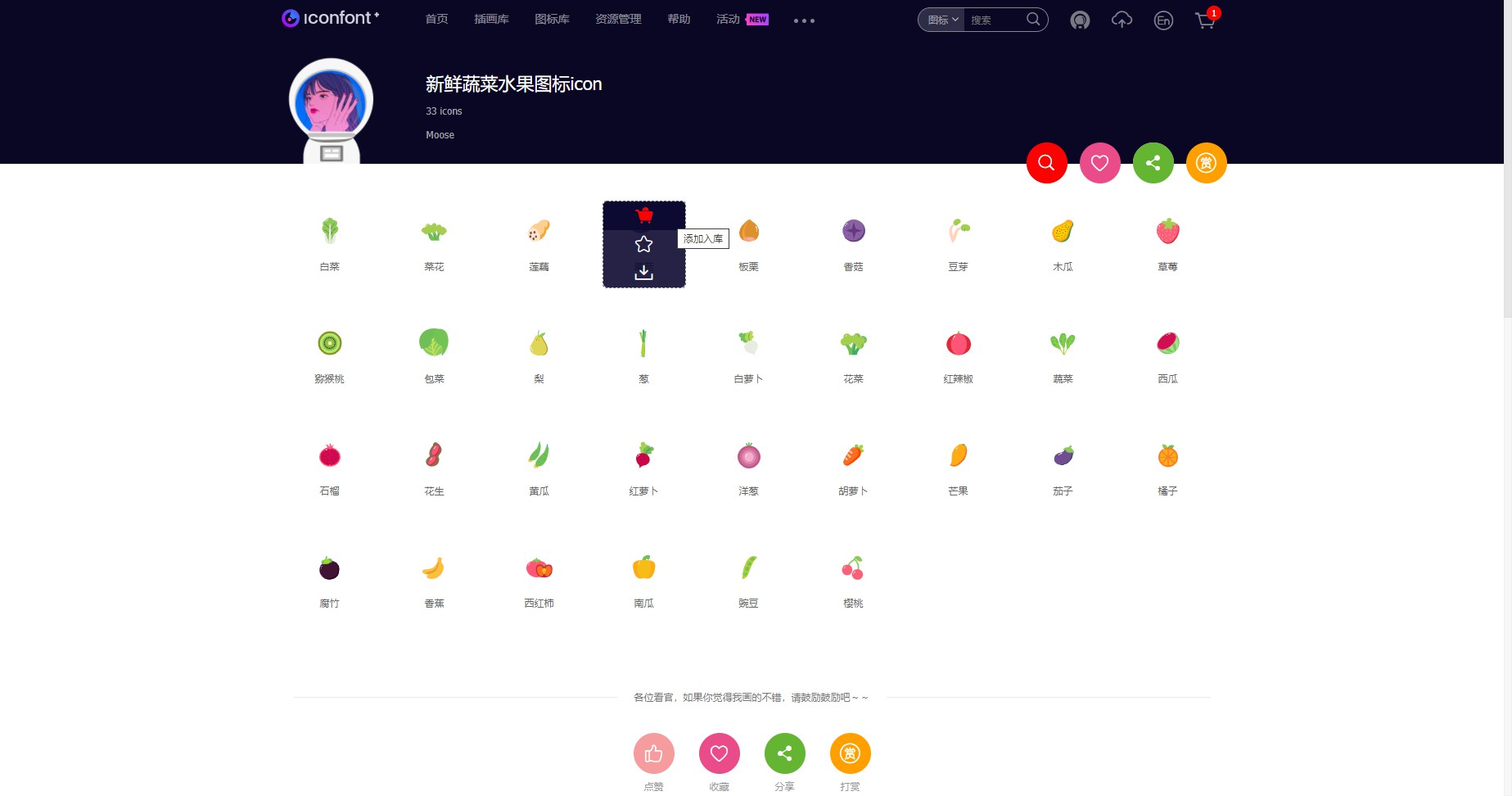
此时右上角的购物车的红色角标变为 1,点一下购物车按钮。
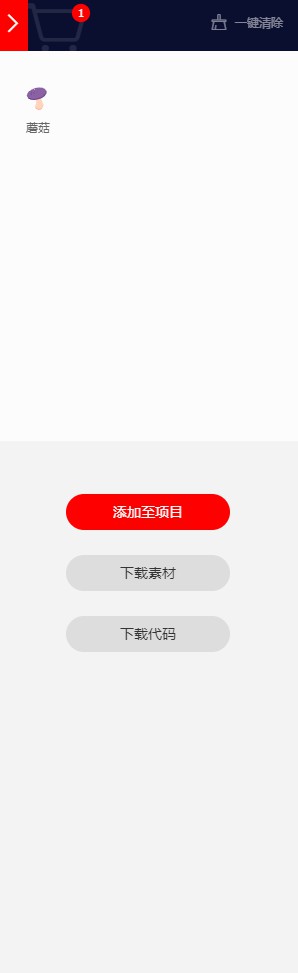
点击『添加至项目』,会弹出以下界面。如果有项目就选择一个;如果没有就新建一个。这里选择 Test 项目。

加入项目后,网页会自动跳转到项目详情界面。此时中间代码区域为灰色。

点击界面中间红色字体『下方新 icon 来袭,点击更新代码,更新后将支持 WOFF2 格式』。

微信小程序代码编写
复制代码,粘贴到 WXSS 中,编写自定义的 iconfont 样式,最后在 icon 组件中引用即可。其代码如下:
@font-face { font-family: 'iconfont'; /* project id 2503355 */ src: url('//at.alicdn.com/t/font_2503355_mfxf6hykc88.eot'); src: url('//at.alicdn.com/t/font_2503355_mfxf6hykc88.eot?#iefix') format('embedded-opentype'), url('//at.alicdn.com/t/font_2503355_mfxf6hykc88.woff2') format('woff2'), url('//at.alicdn.com/t/font_2503355_mfxf6hykc88.woff') format('woff'), url('//at.alicdn.com/t/font_2503355_mfxf6hykc88.ttf') format('truetype'), url('//at.alicdn.com/t/font_2503355_mfxf6hykc88.svg#iconfont') format('svg');}.iconfont{ font-family: 'iconfont'; color: red; font-size: 50px;}.icon-hhh::before{ content: '\e7ed';}
需要注意的是,在 iconfont 中复制的 font-face 代码格式需要转换,将 &#x 转为 \。
WXML 代码如下:
<icon class="iconfont icon-hhh"></icon>
运行效果如下:

如果这个图标不满足我们的需求,可以对这个矢量图标进行修改。
在 阿里巴巴矢量图标库 中将我们要编辑的图标下载到本地,选择『SVG 下载』。
打开 Photoshop 编辑工具 ,选择右上角的『返回旧版』。点击左上角的『文件』,打开刚下载的 SVG 图标。
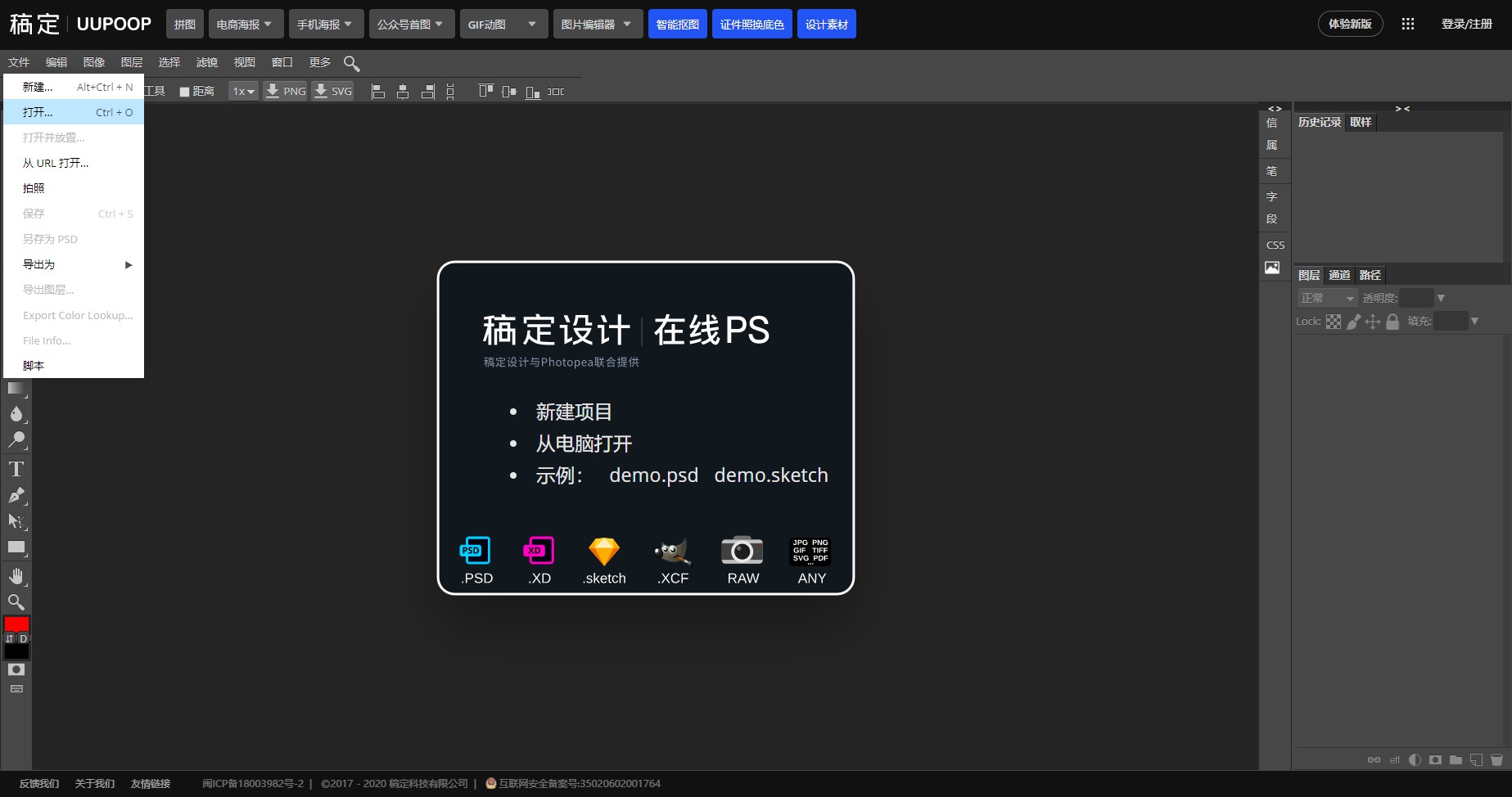
点击图层,可以修改图标的颜色样式,可以添加自定义的图形,比如添加一个矩形。

修改完成后点击左上角的『文件』,导出为 SVG 格式图标。
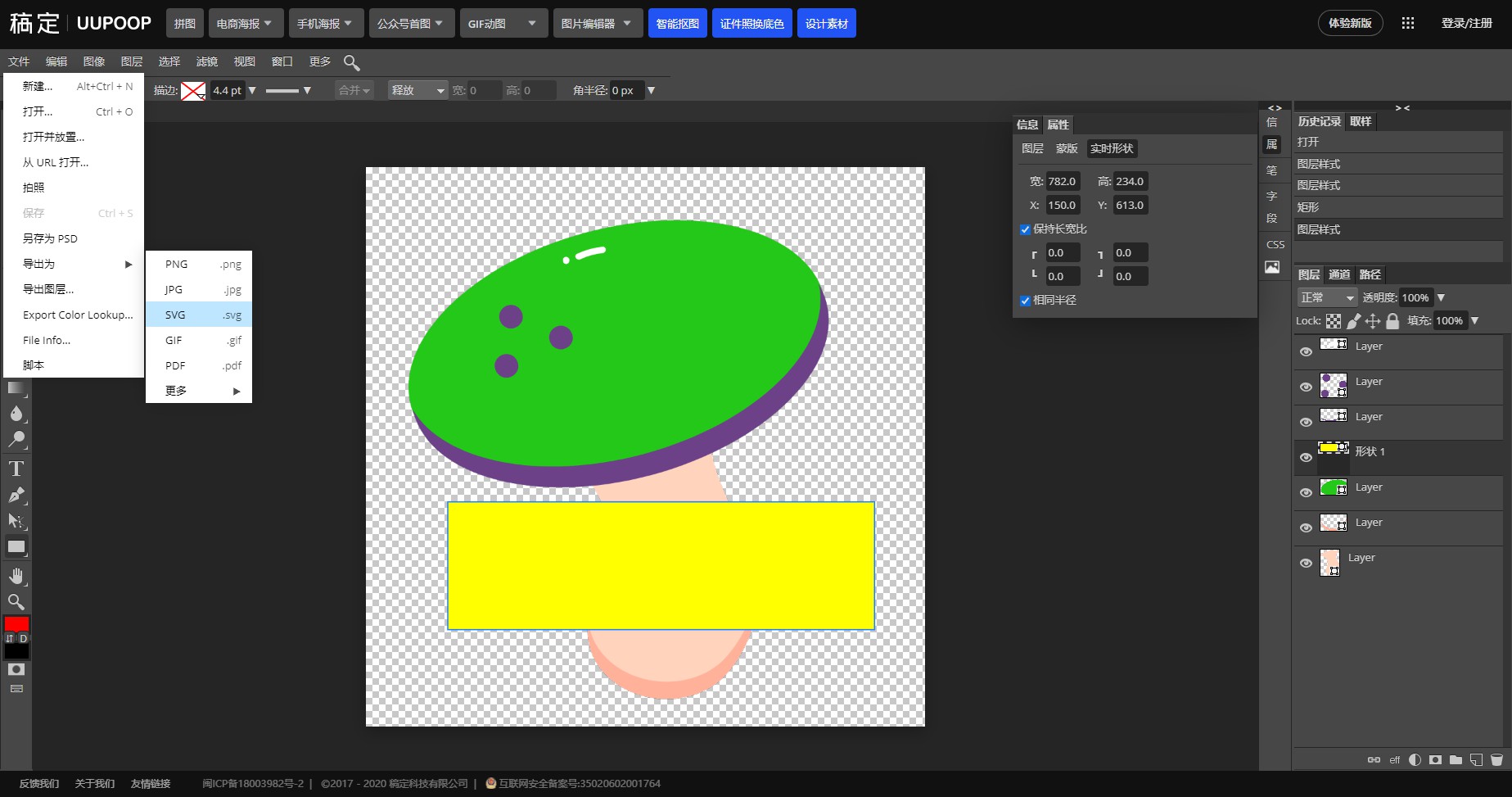
在 阿里巴巴矢量图标库 中,选择要编辑的图标点击『编辑图标』,点击红色字体『点击上传替换 icon』上传 SVG 图标。
这里可以对图层进行编辑,比如旋转、位移等。编辑完后点击『仅保存』。我们需要重新更新一下代码,然后复制到 WXSS 中替换。结果如下:

2、自定义环形进度条
自定义组件
index.wxml:
使用 Canvas 绘制,使用 Component 创建一个自定义组件,例如名字为:circle-progress。在这个组件的 WXML 代码里放置一个 Canvas 组件,该组件用于绘制外面绿色的圆,灰色的圆圈由一个灰色的底圆 bigCircle 加一个白色的稍微小一点的圆 littleCircle 组合出来的。
<view class='canvasBox'> <!-- 外部灰色的圆 --> <view class='bigCircle'></view> <!-- 内部白色的圆 --> <view class='littleCircle'></view> <canvas canvas-id="runCanvas" id="runCanvas" class='canvas'></canvas></view>
index.js:
在自定义组件中,通过一个 percent 的属性标识进度;observer 用于自动监听属性变化,当进度增加时,调用 draw 函数绘制新增的绿色进度条。在 draw 函数及后续调用的函数中,计算出需要绘制的弧度及使用 Canvas 的弧度绘制 Apiece arc 进行绘制是实现环形效果的关键。
Component({ runTimerid:0, behaviors: [], properties: { percent: { type: Number, value: 0, observer: function (newVal, oldVal) { this.draw(newVal); } }, }, data: { percentage: '', //百分比 animTime: '', // 动画执行时间 }, // 私有数据,可用于模版渲染 lifetimes: { // 生命周期函数,可以为函数,或一个在methods段中定义的方法名 attached: function () { }, moved: function () { }, detached: function () { }, }, // 生命周期函数,可以为函数,或一个在methods段中定义的方法名 attached: function () { }, // 此处attached的声明会被lifetimes字段中的声明覆盖 pageLifetimes: { // 组件所在页面的生命周期函数 show: function () { }, }, created() { }, ready() { if (this.data.percent) this.draw(this.data.percent); }, methods: { // 绘制圆形进度条方法 run(c, w, h) { let that = this; var num = (2 * Math.PI / 100 * c) - 0.5 * Math.PI; that.ctx2.arc(w, h, w - 8, -0.5 * Math.PI, num) that.ctx2.setStrokeStyle("#09bb07");//绿色 that.ctx2.setLineWidth("16"); that.ctx2.setLineCap("butt"); that.ctx2.stroke(); that.ctx2.beginPath(); that.ctx2.setFontSize(40); //注意不要加引号 that.ctx2.setFillStyle("#b2b2b2");//浅灰色字体 that.ctx2.setTextAlign("center"); that.ctx2.setTextBaseline("middle"); that.ctx2.fillText(c + "%", w, h); that.ctx2.draw(); }, // 动画效果实现 canvasTap(start, end, time, w, h) { let that = this; start++; if (start > end) { return false; } that.run(start, w, h); that.runTimerid = setTimeout(function () { that.canvasTap(start, end, time, w, h); }, time); }, draw(percent) { const id = 'runCanvas' const animTime = 500 if (percent > 100) return if (!this.ctx2) { // 在自定义组件中,使用 createCanvasContext 创建画布的上下文绘制对象时,需要在第二个参数处传递 this 对象。 // 这样才是在组件中查找画布,不然只是在主页面查找,也就是在引用它的页面查找,这样是查不到的。 const ctx2 = wx.createCanvasContext(id, this) this.ctx2 = ctx2 } let oldPercentValue = this.data.percentage this.setData({ percentage: percent, animTime: animTime }); var time = this.data.animTime / (this.data.percentage-oldPercentValue); // 使用 wx.createSelectorQuery() 创建的对象的 select 方法以 ID 查找组件对象时, // 如果在自定义组件中,必须在查找前先调用一下它的 in 方法,把 this 对象传递进去, // 不然组件是查找不到的,默认组件查询也只仅是在主页面中查找,不会涉及主页面中的子组件。 const query = wx.createSelectorQuery().in(this) query.select('#' + id).boundingClientRect((res) => { var w = parseInt(res.width / 2); var h = parseInt(res.height / 2); if (this.runTimerid) clearTimeout(this.runTimerid) this.canvasTap(oldPercentValue, percent, time, w, h) }).exec() } }})
index.json:
{ "component": true, "usingComponents": {}}
index.wxss:
.canvasBox{ height: 500rpx; position: relative; background-color: white;}/* 外部灰色的圆 */.bigCircle{ width: 420rpx; height: 420rpx; border-radius: 50%; position: absolute; top:0; bottom: 0; left: 0; right: 0; margin: auto auto; background-color: #f2f2f2;}/* 内部白色的圆 */.littleCircle{ width: 350rpx; height: 350rpx; border-radius: 50%; position: absolute; top:0; bottom: 0; left: 0; right: 0; margin: auto auto; background-color: white;}.canvas{ width: 420rpx; height: 420rpx; position: absolute; left: 0; top: 0; bottom: 0; right: 0; margin: auto auto; z-index: 99;}
使用
在使用时,需要先在 JSON 配置中声明对组件的引用。circle-progress 是声明的名称,声明后在 WXML 中就可以把它当做标签使用了。
index.json:
{ "usingComponents": { "circle-progress": "../circle-progress/index" }}
index.wxml:
在 button 触发的 JSON 函数中,模拟网络变化改变进度值,就可以看到动画效果了。
<view class="gap">环形进度条</view><circle-progress id="progress1" percent="{{percentValue}}" /><button bindtap="drawProgress">redraw</button><progress show-info bindtap="onTapProgressBar" stroke-width="11" percent="{{percentValue}}" backgroundColor="#f2f2f2" active-mode="forwards" active bindactiveend="onProgressActiveEnd" border-radius="5" /><button bindtap="onTapReloadBtn">重新加载</button><!-- show-info:代表是否在进度条右侧显示百分比数字,一般不显示,因为进度条本身标明了进度bindtap:绑定 tap 事件,所有可视的 view 组件都可以绑定 tap 事件,即使属性列表中没有显式标明stroke-width:表示进度条的宽度percent:是进度,在 0-100 之间active-mode:是动画停止后重新启动的模式,有两个值:backwards:表示动画从头播;forwards:表示动画从上次结束的位置继续播放。默认值是 backwardsacitve:表示是否展示动画,与 show-info 一样是布尔类型。布尔属性为真,只需要列上属性就行了,如果想显示设置为 false,需要写成 active="{{false}}" 这样的形式bindactiveend:用于绑定动画结束的事件,在动画结束时候触发border-radius:设置进度条外框的圆角大小,默认为 0wx-progress-inner-bar:控制内部已经前进的进度条样式-->
index.js:
onTapProgressBar(e){ console.log(e) let progress = this.data.percentValue if (progress < 100){ progress += 5 this.setData({percentValue:Math.min(100, progress)}) }},onTapReloadBtn(e){ this.setData({percentValue:0}) this.setData({percentValue:100})},drawProgress(){ if (this.data.percentValue >= 100){ this.setData({ percentValue:0 }) } this.setData({ percentValue:this.data.percentValue+10 })}
index.wxss:
drawProgress(){ if (this.data.percentValue >= 100){ this.setData({ percentValue:0 }) } this.setData({ percentValue:this.data.percentValue+10 })}
3、单击预览 rich-text 中的图片并保存
在富文本组件 rich-text 中,节点的事件是被屏蔽的,例如节点里面的图片,它的单击事件是不能监听的。
rich-text 示例代码:
<rich-text space="emsp" nodes="{{nodes}}" bindtap="tap"></rich-text><!--space:控制中文空格显示的大小,有三种值,在中文环境中直接取 emsp 就好。nodes:可以取字符串也可以取数组。如果是字符串的话会影响性能,一般使用数组。-->
nodes 示例代码:
nodes: [{ // nodes 是一个数组,数组中每个元素都可以是复合的 node 节点,也可以是末节的 text 节点,是一个树状结构。简单分辨节点类型的方法,就是看节点有没有 name 属性。 name: 'div', // 节点名称,例如 p、div、span、img、ruby 等,支持大部分 HTML 标签 attrs: {// 表示节点属性,是定义在 HTML 标签上的属性,例如 img 标签的 src、width、height 属性 class: 'div_class', style: 'line-height: 20px;padding:20px;' }, children: [// 代表子节点列表,是一个数组 { type: 'text',// 代表节点类型,有两种:node 与 text,默认是 node,可不写。当类型为 node 时,有 children 属性;为 text,只有 text 属性,text 节点只能包括纯文本 text: '小程序实践' }, { name: 'img', // name 代表标签名称,有 name 代表是复合节点;没有并且 type 属性为 text,代表是简单的文本节点。当是 text 节点时, 它代表的是最基本的文本,没有样式,它所有的样式都是来自父节点的设定 attrs: { src: 'https://caroly.site/caroly_img/%E7%9C%8B%E4%B9%A6%E7%9A%84%E5%A5%B3%E5%AD%A9_1618912429845.jpg', style: 'width:100%' } }, { name: 'img', attrs: { src: 'https://caroly.site/caroly_img/%E8%BF%9E%E8%A1%A3%E5%A5%B3%E5%AD%A9_1618912429933.jpg', style: 'width:100%' // ,style:'width:100%;font-size:0;display:block;'//修改样式 ,class: 'img' } }, { name: 'img', attrs: { src: 'http://caroly.site/caroly_img/86009625_p0_1607479719466.png', style: 'width:100%' } } ]}]
预览保存 rich-text 富文本组件中的图片
在 rich-text 组件上添加 tap 事件,在事件函数中,使用 wx.previewImage 这个接口预览图片,然后选择需要的图片下载。在预览之前需要遍历 rich-text 中的 nodes 数据,将所有图片地址预先取出来。当单击 rich-text 富文本组件时,触发预览,在 tap 事件句柄中,事件对象 e 是一个 TouchEvent 对象,使用它的 pageX、pageY 属性,还可以取到用户大概单击了什么位置。如果以位置可以判断出图片是哪一张,就可以在调用 wx.previewImage 预览图片时,作为第一个参数传递进去,这样就可以实现指定图片的预览与下载了;如果不能确定,取第一张就可以了。
index.wxml:
<rich-text space="emsp" nodes="{{nodes}}" bindtap="tap"></rich-text>
index.js:
data: { nodes: [{ name: 'div', attrs: { class: 'div_class', style: 'line-height: 20px;padding:20px;' }, children: [ { type: 'text', text: '小程序实践' }, { name: 'img', attrs: { src: 'https://caroly.site/caroly_img/%E7%9C%8B%E4%B9%A6%E7%9A%84%E5%A5%B3%E5%AD%A9_1618912429845.jpg', style: 'width:100%' }, class: 'img' }, { name: 'img', attrs: { src: 'https://caroly.site/caroly_img/%E8%BF%9E%E8%A1%A3%E5%A5%B3%E5%AD%A9_1618912429933.jpg', style: 'width:100%' // ,style:'width:100%;font-size:0;display:block;'//修改样式 ,class: 'img' }, class: 'img' }, { name: 'img', attrs: { src: 'http://caroly.site/caroly_img/86009625_p0_1607479719466.png', style: 'width:100%' }, class: 'img' } ] }], urls: [], tagStyle: { img: 'font-size:0;display:block;', }, html:"<div>小程序实践<span>message</span><img src='https://caroly.site/caroly_img/%E8%BF%9E%E8%A1%A3%E5%A5%B3%E5%AD%A9_1618912429933.jpg' /><img src='http://caroly.site/caroly_img/86009625_p0_1607479719466.png' /></div>"},tap(e) { let urls = this.data.urls wx.previewImage({// 预览 current: urls[1], urls: urls })},onReady: function () { // 取出 urls function findUrl(nodes) {// 对 nodes 数据进行遍历,判断节点 name 是不是 img,再看它的属性有没有 src,如果有的话,就推到 urls 数组中去,最后放到 data 中去 let urls = [] nodes.forEach(item => { if (item.name == 'img' && item.attrs) { for (const key in item.attrs) { if (key == 'src') { urls.push(item.attrs[key]) } } } if (item.children) { urls = urls.concat(findUrl(item.children)) } }) return urls } this.data.urls = findUrl(this.data.nodes)}
解决图片之间的间隙问题
如果 rich-text 中有多张图片,上下图片间会有间隙,这是样式问题。小程序的 rich-text 是通过 Web Component 实现的,它不允许外部修改内部的 img 元素的样式,可以直接修改 nodes 数据中的 img 样式,加两个内联样式。
这个缝隙是行内容引起的,通过设置元素为块元素,并设置字体为 0,图片间的间隙就没有了。
.img{ font-size:0; display:block;}
如何插入广告标签、如何将 HTML 文本解析呈现
使用 parset 组件。parset 支持单击预览及下载,并且单击时还向外层派发了一个 imgtap。在使用这个组件时,可以添加一个对 imgtap 事件的监听,在运行时就能拿到被单击图片的网址了。
index.json:
{ "usingComponents": { "circle-progress": "../circle-progress/index", "parser":"../../components/parser/parser" }}
index.wxml:
<parser bindimgtap="onTapImage" html="{{html}}" tag-style="{{tagStyle}}" />
index.js:
onTapImage(e) { // 获取点击的图片网址 console.log('iamge url', e.detail.src)}
4、view 容器组件及 Flex 布局
view 组件是小程序最基础的容器组件,基本上使用它就可以实现所有常见的 UI 布局。
使用 view 实现常见的 UI 布局
view 示例 index.wxml:
<view hober-class="bc_red" class="section_title">parent<!--hover-class:指定按下去的类样式,让容器有一个单击效果。当为 none 或者没有设置属性时,就没有单击态的效果。--><view hover-stop-propagation hober-class="bc_red" class="section_title">child view<!--hover-stop-propagation:该属性可以阻止父节点出现单击态,默认为 fasle,不阻止。注:在运行效果中,子容器有单击态,父容器没有,虽然父容器也设置了 hover-class 属性,但触碰事件被子容器给阻止了。--> </view> </view>
按钮示例 index.wxml:
<!-- 普通按钮 --><view class="section"><button class="btn" type="primary">完成</button></view><!-- 圆形按钮 --><view class="section"><button hover-class="circle-btn__hover_btn"><icon type="success" size="80px"></icon></button></view><!-- 距形按钮 --><view class="section"><button type="default" class="btn" plain hover-class="rect-btn__hover_btn"><icon type="success_no_circle" size="26px"></icon>完成</button></view>
index.wxss:
/* 普通按钮 */.btn{ display: flex; // flex 与 align-items 是为了实现文本与图标的横向对齐 align-items: middle; padding: 8px 50px 8px; border: 1px solid #b2b2b2; background-color: #f2f2f2; width:auto;}/* 圆角按钮 */.circle-btn__hover_btn { opacity: 0.8; transform: scale(0.95, 0.95);// 圆形按钮在单击时缩小 0.05,}/* 方框按钮 */.rect-btn__hover_btn { position: relative; top: 3rpx; left: 3rpx; box-shadow: 0px 0px 8px rgba(175, 175, 175, .2) inset;// 20% 透明格式作为方形按钮按下时状态的内阴影颜色}
Flex 布局
view 容器组件最大的作用就是实现 UI 布局,最常用的是 Flex 布局。
Flex 布局将 display 样式设置为 flex,再加以其他相关的样式实现的布局。
关于 Flex 布局有三个重要的样式:
- justify-content:调整内容在主轴方向的排列方式。
- align-items:对齐元素在辅轴方向的对齐方式。
- align-content:对齐多行内容在辅轴方向上的排列方式。
以默认的 flex-direction 设置为 row 来看,从左到右是主轴,自上而下是侧轴,也叫辅轴。
在这种情况下,justify-content 管制的是元素在 X 方向的排列策略;align-items 管制的是主轴上排列的元素在侧轴方向即 Y 方向的对齐方式;align-content 管制的是当出现多行后,多行内容在辅轴方向上即 Y 轴方向的排列策略。
排列:一般指两个或多个元素它们间隔多少。
对齐:一般指多个元素它们的两边或者中心线对齐的方式。
justify-content:
- flex-start:默认值,元素向主轴的起点看齐。
- flex-end:元素在主轴方向上向尾部看齐。
- center:在主轴方向上居中对齐,有空白再往首尾方向放。
- space-between:向首尾看齐,相当于 align-text 的 justify 效果,两端子元素靠向父容器两端,其他子元素之间的间隔相等。
- space-around:空白在周围均匀分布,元素之间的间隔与父容器之间的间隔是相同的。
align-items:
- stretch:默认值,拉伸填满整个容器。
- flex-start:在辅轴方向上向起点对齐,在默认 X 轴为主轴的情况下,效果看起来是顶部对齐。
- flex-end:向辅轴的终点看齐,当 Y 轴为辅轴时,就是底部对齐。
- center:在辅轴中居中对齐。
- baseline:以子元素的第一行文字对齐的。前面的都是以元素本身所占的区域来定位的,只有这个是以内部的文本去定位的。
flex-wrap:
- no-wrap:默认值,不换行。便于实现多种子元素横向滚动的效果。
- wrap:换行。
- wrap-reverse:换行,第一行在最下面。
flex-direction:用于决定是 X 轴还是 Y 轴是主轴,默认情况下是以 X 轴为主轴。如果将 flex-direction 的值设置为 column,区域块是纵向排列的;如果将 Y 轴定义为主轴,决定元素横向排列的是 align-items。
- row:默认值,从左到右的水平方向为主轴。
- row-reverse:从右到左的水平方向为主轴。
- column:从上到下的垂直方向为主轴。
- column-reverse:从下到上的垂直方向为主轴。
把 view 上的内容绘制到画布上,生成一张海报
view 目前不能直接转绘到画布上,这里有一种可行的办法:先使用 wx.createCanvasContext 创建一个画布,接着在画布上绘制内容、文本或者是图片,再通过 wx.canvasToTempFilePath 保存到本地并获取一个临时图片路径,最后通过 wx.saveImageToPhotosAlbum 保存临时文件到本地相册里。
借助开源的小程序组件 Painter,封装了 JSON 数据绘制海报的功能。
index.wxml:
<view class="section"><!-- 生成分享图,将view转绘为图片 --><button type="primary" class="intro" open-type="getUserInfo" bindgetuserinfo="getUserInfo" wx:if="{{!nickName}}">获取分享图头像昵称</button><button type="primary" class="intro" bindtap="createShareImage" wx:else>点我生成分享图</button><share-box isCanDraw="{{isCanDraw}}" bind:initData="createShareImage" /></view>
index.js:
getUserInfo(e) { this.setData({ nickName: e.detail.userInfo.nickName, avatarUrl: e.detail.userInfo.avatarUrl }) wx.setStorageSync('avatarUrl', e.detail.userInfo.avatarUrl) wx.setStorageSync('nickName', e.detail.userInfo.nickName)},createShareImage() { this.setData({ isCanDraw: !this.data.isCanDraw })}
index.json:
{ "usingComponents": { "circle-progress": "../circle-progress/index", "parser":"../../components/parser/parser", "share-box": "../../components/shareBox/index" }}
5、侧滑删除功能
该功能使用 weui 组件库实现。
weui 组件库可以采用 npm 安装的方式去使用,还可以通过扩展声明的方式进行使用。后者不占用代码包的大小,优先选择后面的方式。
在小程序的配置文件 app.json 文件里,通过 useExtendedLib 配置字段,添加对 weui 引用,添加完后在微信开发者工具的菜单里面,选择工具,构建 npm 构建一下。构建以后就完成了对 weui 组件库的引用配置。
如果是 npm 安装,需要在 app.wxss 文件里添加对 weui.wxss 全局样式的引用;如果是扩展声明这种方式,这种引用代码可以省略。
在 json 文件里面使用 usingComponents 添加对 mp-slideview 组件的引用声明,就可以在 wxml 代码里面使用这个组件。
代码实现
index.wxml:
<view class="page__bd"> <view class="weui-cells"> <mp-slideview ext-class="slideViewClass" buttons="{{slideButtons}}" bindbuttontap="slideButtonTap"> <mp-cell value="标题文字1"></mp-cell> </mp-slideview> </view> <view class="weui-cells"> <mp-slideview buttons="{{slideButtons}}" icon="{{true}}" bindbuttontap="slideButtonTap"> <view class="weui-slidecell"> 左滑可以删除(图标Button) </view> </mp-slideview></view></view>
index.js:
onLoad: function (options) { this.widget = this.selectComponent('.widget') this.setData({ icon: base64.icon20, slideButtons: [{ text: '普通1', src: '/images/icon_love.svg', // icon的路径 },{ text: '普通2', extClass: 'test', src: '/images/icon_star.svg', // icon的路径 },{ type: 'warn', text: '警示3', extClass: 'test', src: '/images/icon_del.svg', // icon的路径 }], });}
index.json:
{ "usingComponents": { "circle-progress": "../circle-progress/index", "parser":"../../components/parser/parser", "share-box": "../../components/shareBox/index", "mp-slideview": "weui-miniprogram/slideview/slideview", "mp-cell": "weui-miniprogram/cell/cell", "slide-view": "../../miniprogram_npm/miniprogram-slide-view/index" }}
6、将视图转为海报
npm install --save wxml-to-canvas
index.wxml:
<view class="page-section"> <view class="page-section-title">wxml</view> <view class="container" > <view class="item-box red"> </view> <view class="item-box green" > <text class="text">yeah!</text> </view> <view class="item-box blue"> <image class="img" src="https://caroly.site/caroly_img/%E8%BF%9E%E8%A1%A3%E5%A5%B3%E5%AD%A9_1618912429933.jpg"></image> </view> </view></view><!-- 渲染wxml --><view class="page-section"> <view class="page-section-title">渲染wxml</view> <!-- 组件 --> <wxml-to-canvas class="widget"></wxml-to-canvas> <view class="page-section-title">导出图片</view> <!-- 图片 --> <image src="{{src}}" style="width: {{width}}px; height: {{height}}px"></image></view><view class="btn-area"> <button type="primary" bindtap="renderToCanvas">渲染到canvas</button> <button bindtap="extraImage">导出图片</button> <button bindtap="onTapSaveBtn">保存图片</button></view>
index.wxss:
.widget {}.container { width: 300px; height: 200px; min-height: 200px; flex-direction: row; justify-content: space-around; background-color: #ccc; align-items: center; padding: 60px 0 60px; display: flex;}.item-box { width: 80px; height: 60px; display: flex;}.red{ background-color: #ff0000}.green { background-color: #00ff00}.blue{ background-color: #0000ff; align-items: center; justify-content: center;}.text{ width: 80px; height: 60px; text-align: center; vertical-align: middle; line-height: 60px;}.img{ width: 40px; height: 40px; border-radius: 50%;}
index.js:
const { wxml, style } = require('./demo')Page({ data: { src: '' }, onLoad() { this.widget = this.selectComponent('.widget') }, onTapSaveBtn(e){ wx.saveImageToPhotosAlbum({ filePath:this.data.src, complete(res) { console.log(res) } }) }, renderToCanvas() { const p1 = this.widget.renderToCanvas({ wxml, style }) p1.then((res) => { console.log('container', res.layoutBox) this.container = res }) }, extraImage() { const p2 = this.widget.canvasToTempFilePath() p2.then(res => { this.setData({ src: res.tempFilePath, width: this.container.layoutBox.width, height: this.container.layoutBox.height }) }) }})
demo.js:
const wxml = `<view class="container" ><view class="item-box red"></view><view class="item-box green" ><text class="text">yeah!</text></view><view class="item-box blue"><image class="img" src="https://caroly.site/caroly_img/%E8%BF%9E%E8%A1%A3%E5%A5%B3%E5%AD%A9_1618912429933.jpg"></image></view></view>`const style = { container: { width: 300, height: 200, flexDirection: 'row', justifyContent: 'space-around', backgroundColor: '#ccc', alignItems: 'center', }, itemBox: { width: 80, height: 60, }, red: { backgroundColor: '#ff0000' }, green: { backgroundColor: '#00ff00' }, blue: { backgroundColor: '#0000ff', alignItems: 'center', justifyContent: 'center', }, text: { width: 80, height: 60, textAlign: 'center', verticalAlign: 'middle', }, img: { width: 40, height: 40, borderRadius: 20, }}module.exports = { wxml, style}
index.json:
{ "usingComponents": { "wxml-to-canvas": "wxml-to-canvas" }}
]]>