Flume 安装
Apache Flume 是一个分布式、可靠、高可用的海量日志聚合系统,支持在系统中定制各类数据发送方,用于收集数据;同时,Flume 可以对数据的简单处理,并写到各种数据接收方。
特点
Flume 的数据流由事件(Event)贯穿始终。事件是 Flume 的基本数据单位,它携带日志数据(字节数组形式)并且携带有头信息,这些 Event 由 Agent 外部的 Source 生成,当 Source 捕获事件后会进行特定的格式化,然后 Source 会把事件推入(单个或多个)Channel 中。可以把 Channel 看作是一个缓冲区,它将保存事件直到 Sink 处理完该事件。Sink 负责持久化日志或者把事件推向另一个 Source。
- Flume 的可靠性
- 当节点出现故障时,日志能够被传送到其他节点上而不会丢失。Flume 提供了三种级别的可靠性保障、从强到弱依次分别为:end - to - end(收到数据 agent 首先将 event 写到磁盘上,当数据传送成功后,再删除;如果数据发送失败,可以重新发送);Store on failure(这也是 scribe 采用的策略,当数据接收方 crash 时,将数据写到本地,待恢复后,继续发送);Besteffort(数据发送到接收方后,不会进行确认)。
- Flume 的可恢复性
- 还是靠 Channel。推荐使用 FileChannel,事件持久化在本地文件系统里(性能较差)。
概念
- Client:Client 生产数据,运行在一个独立的线程。
- Event:一个数据单元,消息头和消息体组成。(Events 可以是日志记录、avro 对象等。)
- Flow:Event 从源点到达目的点的迁移的抽象。
- Agent:一个独立的 Flume 进程,包含组件 Source、Channel、Sink。(Agent 使用 JVM 运行 Flume。每台机器运行一个 Agent,但是可以在一个 Agent 中包含多个 Sources 和 Sinks。)
- Source:数据收集组件。(Source 从 Client 收集数据,传递给 Channel)
- Channel:中转 Event 的一个临时存储,保存由 Source 组件传递过来的 Event。(Channel 连接 Sources 和 Sinks,这个有点像一个队列。)
- Sink:从 Channel 中读取并移除 Event,将 Event 传递到 FlowPipeline 中的下一个 Agent(如果有的话)(Sink 从 Channel 收集数据,运行在一个独立线程。)
Source
Source 是数据的收集端,负责将数据捕获后进行特殊的格式化,将数据封装到事件(Event)里,然后将事件推入 Channel 中。
Flume 提供了各种 Source 的实现,包括 Avro Source、Exce Source、Spooling Directory Source、NetCat Source、Syslog Source、Syslog TCP Source、Syslog UDP Source、HTTP Source、HDFS Source、etc。如果内置的 Source 无法满足需要,Flume 还支持自定义 Source。
Sink
Flume Sink 取出 Channel 中的数据,进行相应的存储文件系统,数据库,或者提交到远程服务器。
Flume 也提供了各种 Sink 的实现,包括 HDFS sink、Logger sink、Avro sink、File Roll sink、Null sink、HBase sink、etc。
Flume Sink 在设置存储数据时,可以向文件系统中,数据库中,Hadoop 中存储数据,在日志数据较少时,可以将数据存储在文件系统中,并且设定一定的时间间隔保存数据。在日志数据较多时,可以将相应的日志数据存储到 Hadoop 中,便于日后进行相应的数据分析。
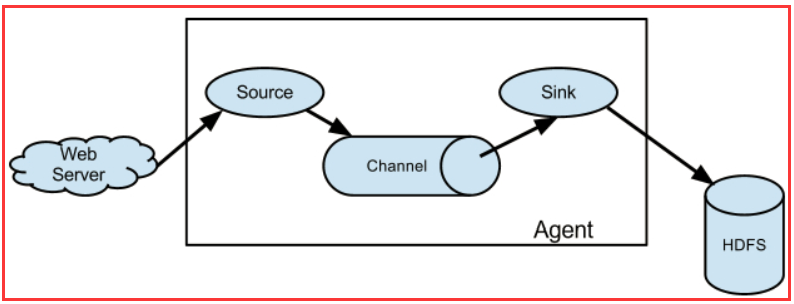
Flume NG 的体系结构
Flume 运行的核心是 Agent。Flume 以 Agent 为最小的独立运行单位。一个 Agent 就是一个 JVM。它是一个完整的数据收集工具,含有三个核心组件:Source、Channel、Sink。通过这些组件,Event 可以从一个地方流向另一个地方。
Flume 安装
上传解压(『caroly02』)
tar xf apache-flume-1.6.0-bin.tar.gz -C /opt/caroly/ cd /opt/caroly mv apache-flume-1.6.0-bin/ flume修改配置文件
cd flume/conf/mv flume-env.sh.template flume-env.shvi flume-env.shchange 22: export JAVA_HOME=/usr/java/jdk1.8.0_251-amd64
vi fk.confa1.sources = r1 a1.sinks = k1 a1.channels = c1 # Describe/configure the source a1.sources.r1.type = avro a1.sources.r1.bind = caroly02 a1.sources.r1.port = 41414 # Describe the sink a1.sinks.k1.type = org.apache.flume.sink.kafka.KafkaSink a1.sinks.k1.topic = testflume a1.sinks.k1.brokerList = caroly02:9092,caroly03:9092,caroly04:9092 a1.sinks.k1.requiredAcks = 1 a1.sinks.k1.batchSize = 20 # Use a channel which buffers events in memory a1.channels.c1.type = memory a1.channels.c1.capacity = 1000000 a1.channels.c1.transactionCapacity = 10000 # Bind the source and sink to the channel a1.sources.r1.channels = c1 a1.sinks.k1.channel = c1
启动
需先启动 Zookeeper 和 Kafkabin/flume-ng agent -n a1 -c conf -f conf/fk.conf -Dflume.root.logger=DEBUG,console