


Hadoop(五)Hive 多节点搭建
环境准备
-
基于 Hadoop集群 继续搭建多节点『Hive』。
-
确保四台虚拟机互通。
Hive架构
| caroly01 | caroly02 | caroly03 | caroly04 |
|---|---|---|---|
| MySQL元数据服务 | 单节点 | 服务端 | 客户端 |
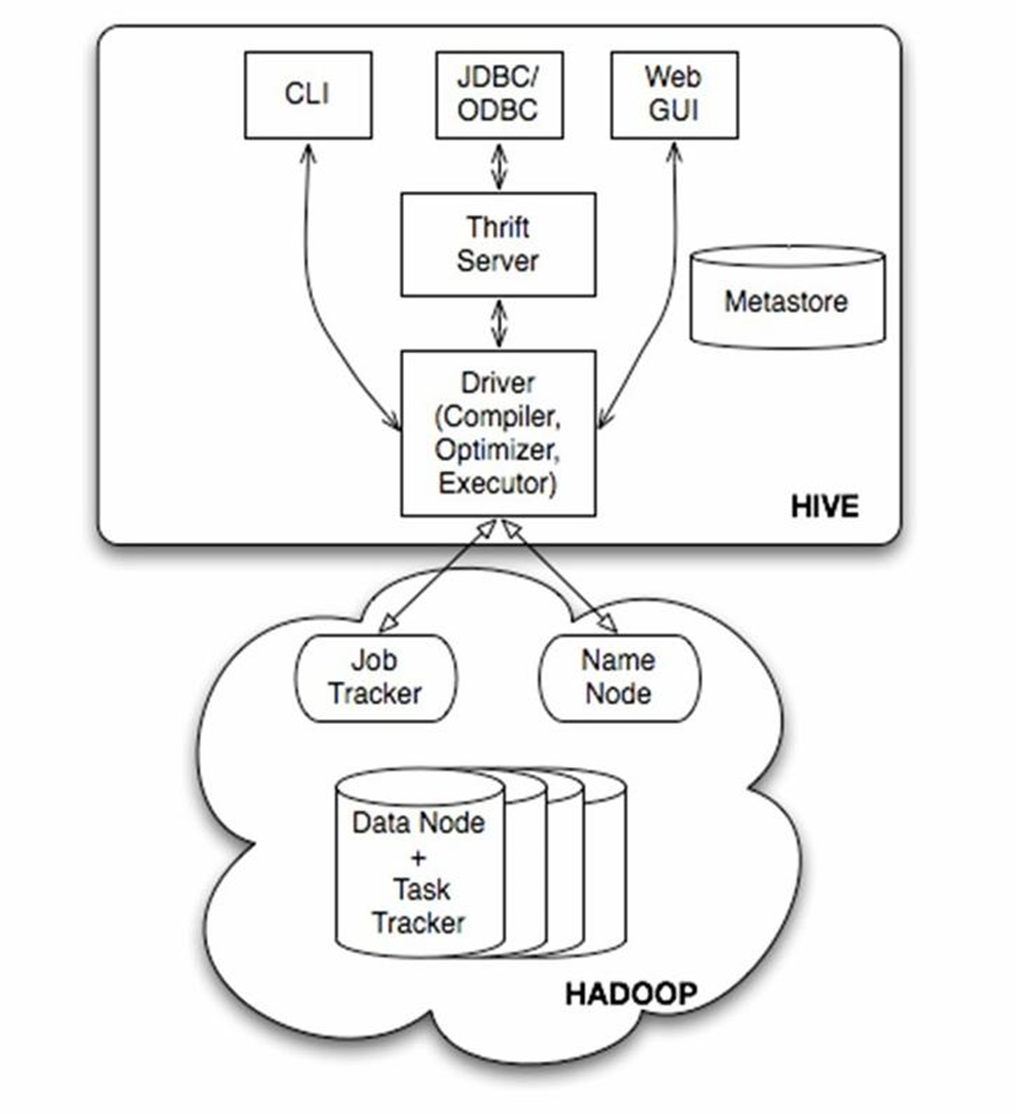
- 用户接口主要有三个:CLI、Client 和 WUI。其中最常用的是 CLI,CLI 在启动的时候,会同时启动一个 Hive 副本。Client 是 Hive 的客户端,用户连接至 Hive Server。在启动 Client 模式的时候,需要指出 Hive Server所在节点,并且在该节点启动 Hive Server。WUI 是通过浏览器访问 Hive。
- Hive 将元数据存储在数据库中,如 MySQL、derby。Hive 中的元数据包括表的名字,表的列和分区及其属性,表的属性(是否为外部表等),表的数据所在目录等。
- 解释器、编译器、优化器完成 HQL 查询语句从词法分析、语法分析、编译、优化以及查询计划的生成。生成的查询计划存储在 HDFS 中,并在随后由 MapReduce 调用执行。
- Hive的数据存储在 HDFS 中,大部分的查询、计算由 MapReduce 完成(包含 * 的查询,比如:select * from tbl 不会生成 MapReduce 任务)。
- 编译器将一个 Hive SQL 转换操作符,操作符是 Hive 的最小处理单元,每个操作符代表 HDFS 的一个操作或者一道 MapReduce 作业。
Hive配置
启动『Hadoop集群』,通过『jps』命令查看启动状况。
安装MySQL
在『caroly01』中安装关系型数据库(MySQL):
yum install mysql-server -y // yum安装mysql
service mysqld start // 启动mysql服务
mysql // 无密码进入mysql
select host,user,password from user; // 查询有哪些用户
grant all privileges on *.* to 'root'@'%' identified by '123' with grant option; // 修改root密码为123,并远程访问
delte from user where host!='%'; // 删除非%用户
flush privileges; // 刷新
quit; // 退出
mysql -u root -p 123 // 有密码进入mysql
单用户模式
搭建单节点
在『caroly02』中解压『Hive』安装包到指定目录:
cd ~/software
tar xf apache-hive-1.2.1-bin.tar.gz
mv apache-hive-1.2.1-bin hive
cp -r hive /opt/caroly/
配置环境变量:
vi /etc/profile +
export HIVE_HOME=/opt/caroly/hive
PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$ZOOKEEPER_HOME/bin:$HIVE_HOME/bin
. /etc/profile
修改『Hive』配置文件:
cd /opt/caroly/hive/conf/
mv hive-default.xml.template hive-site.xml
vi hive-site.xml
光标定位到<configuration>这一行
:.,$-1d
将configuration之间的删除,新添如下,保存退出(:wq):
<property> <!-- 本机表默认位置 -->
<name>hive.metastore.warehouse.dir</name>
<value>/user/hive_remote/warehouse</value>
</property>
<property> <!-- 包含元数据的数据存储的JDBC连接字符串 -->
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://caroly01/hive_remote?createDatabaseIfNotExist=true</value>
</property>
<property> <!-- 包含元数据的数据存储的JDBC驱动程序类名称 -->
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<property> <!-- 用户名 -->
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<property> <!-- 密码 -->
<name>javax.jdo.option.ConnectionPassword</name>
<value>123</value>
</property>
执行『Hive』:
hive
如果报错:Exception in thread "main" java.lang.RuntimeException: java.lang.RuntimeException: Unable to instantiate org.apache.hadoop.hive.ql.metadata.SessionHiveMetaStoreClient
将mysql驱动包放入 hive 的 lib 目录中。
如果报错:The specified datastore driver ("com.mysql.jdbc.Driver") was not find in the CLASSPATH.
将mysql驱动包放入 hive 的 lib 目录中。
如果报错:java.lang.IncompatibleClassChangeError: Found class jline, Terminal, but interface was expected
cd /opt/caroly/hive/lib
可以找到有一个 jline-2.12.jar
cd /opt/caroly/hadoop-2.9.2/share/hadoop/yarn/lib
发现同样有一个 jline的jar包,但是版本不一样,将低版本的删掉。
rm -rf jline-*.jar
cp /opt/caroly/hive/lib/jline-2.12.jar /opt/caroly/hadoop-2.9.2/share/hadoop/yarn/lib
在『caroly01』中创建表:
create table tbl(id int, age int);
show tables;
insert into tbl values(1,1);
select * from tbl;
在本地浏览器访问:
caroly03:8088
可以看到有执行一条sql语句。
在本地浏览器访问:
caroly01:50070
点击:Utilities --> Browse the file system
访问此目录:/user/hive_remote/warehouse
可以发现上传成功。
MySQL中同样可以看到:
mysql -u root -p 123
show databases;
use hive_remote;
show tables;
select * from TBLS;
select * from COLUMNS_V2;
多节点搭建
将『hive』目录分发给『caroly03』、『caroly04』:
scp -r /opt/caroly/hive/ caroly03:/opt/caroly/
scp -r /opt/caroly/hive/ caroly04:/opt/caroly/
在『caroly03』和 『caroly04』中都配置环境变量:
vi /etc/profile +
export HIVE_HOME=/opt/caroly/hive
PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$ZOOKEEPER_HOME/bin:$HIVE_HOME/bin
. /etc/profile
在『caroly03』中修改如下:
cd /opt/caroly/hive/conf
vi hive-site.xml
修改前两项如下:
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/user/hive/warehouse</value>
</property>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://caroly01/hive?createDatabaseIfNotExist=true</value>
</property>
在『caroly04』中删除所有
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/user/hive/warehouse</value>
</property>
<property>
<name>hive.metastore.uris</name>
<value>thrift://caroly03:9083</value>
</property>
在『caroly03』中执行:
hive --service metastore
注:这是一个阻塞式窗口,卡住不动是正常现象。
新开一个『caroly03』, 执行:
ss -nal
发现会有端口为 9803 的服务,表面元数据已启动好。
在『caroly04』中执行:
hive
create table psn1(id int);
insert into psn1 values(1);
在『caroly01』中可以看到有多了一张表:hive
同样在『caroly01:50070』中可以看到目录/user/hive/warehouse中有psn1
在『caroly02』中执行:
hdfs dfs -cat /user/hive_remote/warehouse/tbl/*
发现输出:11
查看分隔符:
hdfs dfs -get /user/hive_remote/warehouse/tbl/*
cat -A 000000_0
输出如下:1^A1$
说明^A为分隔符,这是默认分隔符。
建表写数据
举例表中数据如下:
1,张三1,dota-book-movie,beijng:wudaokou-shanghai:pudong
2,张三2,dota-book-movie,beijng:wudaokou-shanghai:pudong
3,张三3,dota-movie,beijng:wudaokou-shanghai:pudong-shenzhen:nanshan
4,张三4,dota-book,beijng:wudaokou-shanghai:pudong
5,张三5,dota-book-movie,shanghai:pudong
6,张三6,dota-book,beijng:wudaokou-shanghai:pudong
其中,第一列类型为『int』,第二列为『string』,第三列为『array』,第四列为『map』。
建表语句如下:
hive> create table psn
(
id int,
name string,
likes array,
address map<string,string>
)
row format delimited
fields terminated by ','
collection items terminated by '-'
map keys terminated by ':';
- row format delimited:分隔符设置开始语句。必须在其它分隔设置之前,也就是分隔符设置语句的最前。
- fields terminated by ',':设置字段与字段之间的分隔符为","。
- collection items terminated by '-':设置一个复杂类型(array, struct)字段的各个item之间的分隔符为"-"。
- map keys terminated by ':':设置一个复杂类型(map)字段的key-value之间的分隔符为":"。
- lines terminated by '':设置行与行之间的分隔符。此处未设置。
看一下刚建表的结构:
hive> desc formatted psn;
hive> desc formatted psn;
OK
# col_name data_type comment
id int
name string
likes array<string>
address map<string,string>
# Detailed Table Information
Database: default
Owner: root
CreateTime: Sun May 17 21:54:23 CST 2020
LastAccessTime: UNKNOWN
Protect Mode: None
Retention: 0
Location: hdfs://mycluster/user/hive/warehouse/psn
Table Type: MANAGED_TABLE
Table Parameters:
transient_lastDdlTime 1589723663
# Storage Information
SerDe Library: org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe
InputFormat: org.apache.hadoop.mapred.TextInputFormat
OutputFormat: org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat
Compressed: No
Num Buckets: -1
Bucket Columns: []
Sort Columns: []
Storage Desc Params:
colelction.delim -
field.delim ,
mapkey.delim :
serialization.format ,
Time taken: 0.168 seconds, Fetched: 32 row(s)
可以看到Storage Desc Params中有多出刚刚指定的格式,并且Table Type显示为内部表。
写入数据:
mkdir data
cd data/
vi data
将上述举例数据复制到data文件中。
hive> load data local inpath '/root/data/data' into table psn;
hive> select * from psn;
如果查询的时候希望看到字段名称,需要配置如下:
hive> set hive.cli.print.header=true;
创建usr目录并上传一份数据文件:
hdfs dfs -mkdir /usr
hdfs dfs -put data /usr/
创建外部表:
create external table psn2
(
id int,
name string,
likes array,
address map<string,string>
)
row format delimited
fields terminated by ','
collection items terminated by '-'
map keys terminated by ':'
location '/usr/';
查看表内容,发现表中已有数据:
select * from psn2;
查看表详细结构,发现Table Type为EXTERNAL_TABLE。
hive> desc formatted psn2;
OK
... ...
Table Type: EXTERNAL_TABLE
... ...
Time taken: 0.117 seconds, Fetched: 38 row(s)
内外表的区别:
- 创建表的时候,内部表直接存储在默认的hdfs路径;外部表需要指定路径。
- 删除表的时候,内部表会将数据和元数据全部删除;外部表只删除元数据,数据不删除。
注:hive:读时检查(实现解耦,提高数据记载的效率);关系型数据库:写时检查。
分区
单分区
hive> create table psn3
(
id int,
name string,
likes array,
address map<string,string>
)
partitioned by(age int)
row format delimited
fields terminated by ','
collection items terminated by '-'
map keys terminated by ':';
查看表详细结构:
hive> desc formatted psn3;
OK
# col_name data_type comment
id int
name string
likes array<string>
address map<string,string>
# Partition Information
# col_name data_type comment
age int
... ...
导入分区数据(本地上传是copy,hdfs上传是move):
load data local inpath '/root/data/data' into table psn3 partition(age=10);
双分区
hive> create table psn4
(
id int,
name string,
likes array,
address map<string,string>
)
partitioned by(age int,sex string)
row format delimited
fields terminated by ','
collection items terminated by '-'
map keys terminated by ':';
导入分区数据:
hive> load data local inpath '/root/data/data' into table psn4 partition(age=20,sex='man');
创建目录(partition的顺序非固定:按字段名匹配。):
hive> alter table psn4 add partition(age=30,sex='boy');
删除目录(可以只删除一个):
hive> alter table psn4 drop partition(sex='min');
修复分区:
hive> msck repair table psn4;
清空表数据:
hive> truncate table psn4;
插入数据二:
hive> create table psn10
(
id int,
name string
)
row format delimited
fields terminated by ',';
hive> create table psn11
(
id int,
likes array
)
row format delimited
fields terminated by ','
collection items terminated by '-';
hive> FROM psn
INSERT OVERWRITE TABLE psn10
SELECT id,name
insert into psn11
select id,likes
hiveserver2、beeline
在『caroly03』中执行:
hiveserver2
注:这也是一个阻塞式窗口,卡住不动是正常现象。
在『caroly04』中执行:
beeline
beeline> !connect jdbc:hive2://caroly03:10000/default root xxx
beeline> show tables;
后面的root以及xxxx可随意填写,但不能为空。
于eclipse中编写如下代码:
import java.sql.Statement;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.ResultSet;
import java.sql.SQLException;
public class HiveJdbcClient {
private static String driverName = "org.apache.hive.jdbc.HiveDriver";
public static void main(String[] args) throws SQLException {
try {
Class.forName(driverName);
} catch (ClassNotFoundException e) {
e.printStackTrace();
}
Connection conn= DriverManager.getConnection("jdbc:hive2://caroly03:10000/default", "root", "");
Statement stmtStatement= conn.createStatement();
String sqlString= "select * from psn limit 5";
ResultSet resultSet= stmtStatement.executeQuery(sqlString);
while (resultSet.next()) {
System.out.println(resultSet.getString(1)+ "_"+ resultSet.getString("name"));
}
}
}
可通过代码操作数据。
动态分区
开启支持动态分区:
# 设为true打开动态分区功能
hive> set hive.exec.dynamic.partition=true;
# strice默认有一个分区列是静态分区;nostrice可全部为动态分区
hive> set hive.exec.dynamic.partition.mode=nostrice;
# 每一个执行 mr 节点上,允许创建的动态分区的最大数量(100)
hive> set hive.exec.max.dynamic.partitions.pernode;
# 所有执行 mr 节点上,允许创建的所有动态分区的最大数量(1000)
hive> set hive.exec.max.dynamic.partitions;
# 所有的 mr job 允许创建的文件的最大数量(100000)
hive> set hive.exec.max.created.files;
创建两张表:
hive> create table psn21
(
id int,
name string,
age int,
gender string,
likes array<string>,
address map<string,string>
)
row format delimited
fields terminated by ','
collection items terminated by '-'
map keys terminated by ':';
hive> create table psn22
(
id int,
name string,
likes array<string>,
address map<string,string>
)
partitioned by(age int, gender string)
row format delimited
fields terminated by ','
collection items terminated by '-'
map keys terminated by ':';
数据文件为 data4:
1,张三1,12,max,lol-book-movie,beijng:wudaokou-shanghai:pudong
2,张三2,11,man,lol-book-movie,beijng:wudaokou-shanghai:pudong
3,张三3,12,man,lol-movie,beijng:wudaokou-shanghai:pudong-shenzhen:nanshan
4,张三4,11,min,lol-book,beijng:wudaokou-shanghai:pudong
5,张三5,11,max,lol-book-movie,shanghai:pudong
6,张三6,12,man,lol-book,beijng:wudaokou-shanghai:pudong
导入到初始表中:
hive> load data local inpath '/root/data/data4' into table psn21;
执行 SQL 语句如下:
hive> from psn21
insert into psn22 partition(age,gender)
select id,name,likes,address,age,gender
通过select语句查询发现动态分区表现的不明显,访问caroly01:50070,依次进入:Utilities -> Browse the file system -> user -> hive -> warehouse -> psn22 。可以发现有多个分区。
分桶
开启支持分桶:
# 设置为true之后,mr运行时会根据bucket的个数自动分配reduce task个数。
# 注意:一次作业产生的桶(文件数量)和reduce task个数一致。
hive> set hive.enforce.bucketing=true;
创建一张表:
hive> create table psn31( id int, name string, age int)
row format delimited fields terminated by ',';
测试数据如下:
1,tom,11
2,cat,22
3,dog,33
4,hive,44
5,hbase,55
6,mr,66
7,alice,77
8,scala,88
将数据导入表中:
hive> load data local inpath '/root/data/bucket' into table psn31;
分桶表:
hive> create table psn_pucket( id int, name string, age int)
clustered by(age) into 4 buckets
row format delimited fields terminated by ',';
写入数据:
hive> insert into psn_pucket select id,name,age from psn31;
查看桶中数据:
hdfs dfs -cat /user/hive/warehouse/psn_pucket/000000_0
hdfs dfs -cat /user/hive/warehouse/psn_pucket/000001_0
hdfs dfs -cat /user/hive/warehouse/psn_pucket/000002_0
hdfs dfs -cat /user/hive/warehouse/psn_pucket/000003_0
或:
select * from psn_pucket tablesample(bucket 1 out of 4);
select * from psn_pucket tablesample(bucket 2 out of 4);
select * from psn_pucket tablesample(bucket 3 out of 4);
select * from psn_pucket tablesample(bucket 4 out of 4);
总结
本文由 caroly 创作,如果您觉得本文不错,请随意赞赏
采用 知识共享署名4.0 国际许可协议进行许可
本站文章除注明转载 / 出处外,均为本站原创或翻译,转载前请务必署名
原文链接:https://caroly.fun/archives/hive多节点搭建
最后更新:2021-04-29 16:07:41




{kind=link}