


Hadoop(二)WordCount(单词统计)详解
MapReduce理论简介
MapReduce编程模型
『MapReduce』是一种可用于数据处理的编程模型。它的任务过程分为两个处理阶段: map 阶段和 reduce 阶段。每阶段都以 键-值对 作为输入和输出,其类型由我们按需选择。我们还需要写两个函数: map 函数和 reduce 函数。
map 函数由『Mapper』类来表示,后者声明一个抽象的 map() 方法。『Mapper』类是一个泛型类型,它有四个形参类型,分别指定 map 函数的输入键、输入值、输出键、输出值的类型。
同样, reduce 函数也有四个形式参数类型用于指定输入和输出类型。 reduce 函数的输入类型必须匹配 map 函数的输出类型。
MapReduce处理过程
处理过程
『MapReduce』作业(job)对象指定作业执行规范,是客户端需要执行的一个工作单元:包括输入数据、『MapReduce』程序和配置信息。
Configuration conf= new Configuration();
Job job= Job.getInstance(conf);
我们可以用它来控制整个作业的运行。我们在『Hadoop』集群上运行这个作业时,要把代码打包成一个『JAR』文件(『Hadoop』在集群上发布这个文件)。不必明确指定『JAR』文件的名称,在『Job』对象的『setJarByClass()』方法中传递一个类即可,『Hadoop』利用这个类来查找包含它的『JAR』文件,进而找到相关的『JAR』文件。
job.setJarByClass(MyWordCount.class);
对『Job』进行合理的命名有助于更快地找到『Job』,以便在『JobTracker』和『Tasktracker』的页面中对其进行监视。
job.setJobName("myjob");
构造『Job』对象后,需要指定输入和输出数据的路径。调用『FileInputFormat』类的静态方法『addInputPath()』来定义输入数据的路径,这个路径可以是单个的文件、一个目录(此时,将目录下的所有文件当作输入)或符合特定文件模式的一系列文件。由函数名可知,可以多次调用『addInputPath()』来实现多路径的输入。
Path inPath= new Path("/user/root/test.txt");
FileInputFormat.addInputPath(job, inPath);
调用『FileOutputFormat』类中的静态方法,『setOutputPath()』来指定输出路径(只能有一个输出路径)。这个方法指定的是『reduce』函数输出文件的写入目录。在运行作业前该目录是不应该存在的(或者是空目录),否则『Hadoop』会报错并拒绝运行作业。这种预防措施的目的是防止数据丢失(长时间运行的作业如果结果被意外覆盖,肯定是非常恼人的)。
Path outPath= new Path("/output/wordcount");
// 如果输出路径存在,则先删除
if(outPath.getFileSystem(conf).exists(outPath)) {
outPath.getFileSystem(conf).delete(outPath, true);
}
FileOutputFormat.setOutputPath(job, outPath);
接着,通过『setMapperClass()』和『setReducerClass()』方法指定要用的『map』类型和『reduce』类型。
job.setMapperClass(MyMapper.class);
job.setReducerClass(MyReducer.class);
『setOutputKeyClass()』和『setOutputValueClass()』方法控制『reduce』函数的输出类型,并且必须和『Reduce』类产生的相匹配。『map』函数的输出类型默认情况下和『reduce』函数是相同的,因此如果『mapper』产生出和『reducer』相同的类型时,不需要单独设置。但是,如果不同,则必须通过『setMapOutputKeyClass()』和『setMapOutputValueClass()』方法来设置map函数的输出类型。
job.setMapOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
在设置定义『map』和『reduce』函数的类之后,可以开始运行作业。『Job』中的『waitForCompletion()』方法提交作业并等待执行完成。该方法唯一的参数是一个标识,指示是否已生成详细输出。当标识位『true』(成功)时,作业会把其进度信息写到控制台。
job.waitForCompletion(true);
『waitForCompletion()』方法返回一个布尔值,表示执行的成败,这个布尔值被转换成程序的退出代码『0』或者『1』。
打包并运行WordCount程序
Eclipse环境搭建
将下载好的『hadoop-2.9.2.tar.gz』和『hadoop-2.9.2-src.tar.gz』解压到英文路径下,并创建『hadoop-2.9.2-lib』目录。
将『E:\caroly\hadoop-2.9.2\share\hadoop』目录下文件夹的根目录(除『httpfs』、『kms』)中的『jar』包和『lib』中的『jar』包复制到『hadoop-2.9.2-lib』目录。
配置Windows环境变量:
HADOOP_HOME:E:\caroly\hadoop-2.9.2
HADOOP_USER_NAME:root
Path:%HADOOP_HOME%\bin;
解压此文件夹并将里面的所有文件替换到『E:\caroly\hadoop-2.9.2\bin』中。
将『E:\caroly\hadoop-2.9.2\bin』中的『hadoop.dll』放到『C:\Windows\System32』中。
将『hadoop-eclipse-plugin-2.6.0.jar』放到『Eclipse』的安装目录『D:\eclipse\plugins』中。
打开『Eclipse』,在『Project Explorer』中会出现『DFS Locations』。
如果没有,点击右上角『Java EE』按钮,切换到『Java EE』项目下。
点击:Windows --> Preferences --> Hadoop Map/Reduce 。右边选择Hadoop路径。

依次点击:Windows --> Show View --> Other... --> MapReduce Tools --> Map/Reduce Locations 。
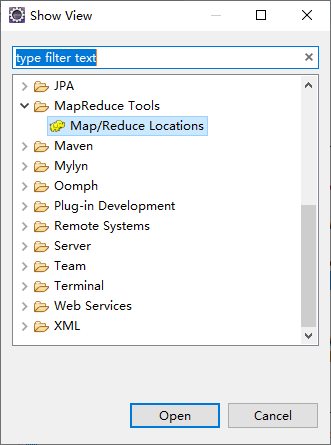
在『Map/Reduce Locations』面板中右键,选择『New Hadoop location...』。
在定位器中输入名称、去掉『DFS Master』面板中『Use M/R Master host』前面的勾,填入状态为『active』的主机名以及端口。

创建环境共享『jar』包:
依次点击:Windows --> Preferences --> Java --> Build Path --> User Libraries 。

点击『New...』,填入自定义名称。注:System library(added to the boot class path)前面不要勾选。

点击确定后面板中会出现『hadoop507_jars』。点击右侧的『Add External JARs...』,选择『E:\caroly\hadoop-2.9.2-lib』中的所有『jar』包。点击『Apply and Close』退出。

新建『Java』项目,右键项目选择Build Path --> Configure Build Path... 。
依次点击:Add Library... --> User Library 。选择刚刚创建的自定义共享包。
依次点击:Add Library... --> JUnit 。导入『Junit 4』。

将『caroly01』中的『Hadoop』配置文件(core-site.xml、hdfs-site.xml、mapred-site.xml、yarn-site.xml)复制到『src』下。
代码逻辑
MyWordCount.java
package com.caroly.mr.wc;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class MyWordCount {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
Configuration conf= new Configuration();
Job job= Job.getInstance(conf);
job.setJarByClass(MyWordCount.class);
job.setJobName("myjob");
Path inPath= new Path("/user/root/test.txt");
FileInputFormat.addInputPath(job, inPath);
Path outPath= new Path("/output/wordcount");
//如果输出路径存在,则先删除
if(outPath.getFileSystem(conf).exists(outPath)) {
outPath.getFileSystem(conf).delete(outPath, true);
}
FileOutputFormat.setOutputPath(job, outPath);
job.setMapperClass(MyMapper.class);
job.setReducerClass(MyReducer.class);
job.setMapOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
job.waitForCompletion(true);
}
}
MyMapper.java
package com.caroly.mr.wc;
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
public class MyMapper extends Mapper<Object, Text, Text, IntWritable>{
private final static IntWritable one = new IntWritable(1);
private Text word= new Text();
public void map(Object key, Text value, Context context) throws IOException, InterruptedException{
StringTokenizer itr= new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
context.write(word, one);
}
}
}
MyReducer.java
package com.caroly.mr.wc;
import java.io.IOException;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.mapreduce.Reducer;
public class MyReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
//迭代计算
private IntWritable result= new IntWritable();
public void reduce(Text key, Iterable<IntWritable> values,
Context context) throws IOException, InterruptedException {
int sum= 0;
for (IntWritable val : values) {
sum+= val.get();
}
result.set(sum);
context.write(key, result);
}
}
运行并查看结果
在『caroly01』中运行如下『shell』
for i in `seq 100000`;do echo "hello caroly $i" >> test.txt;done
会在当前目录生成一个大小为『1.9M』的『txt』文件。
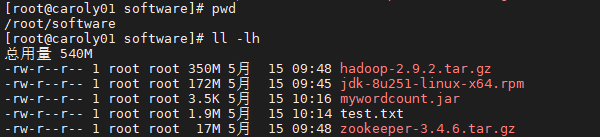
将这个文件上传到HDFS中:
hdfs dfs -mkdir -p /user/root
hdfs dfs -D dfs.blocksize=1048576 -put ~/software/test.txt /user/root
上传的测试文件分为两块,第一块大小是『1M』,第二块的大小为剩余字节大小。
将写好的单词统计代码打包成『jar』包。
右键此包--> Export... --> Java --> JAR file 。

将生成的『jar』包放到『caroly01』中。
运行如下命令进行单词统计:
hadoop jar ~/software/mywordcount.jar com.caroly.mr.wc.MyWordCount
运行如下命令查看结果:
hdfs dfs -cat /output/wordcount/part-r-00000
WordCount处理过程
一、将文件拆分成 splits,并将文件按行分割形成 <key, value> 形式。这一步由 MapReduce 框架自动完成,其中偏移量(即 key 的值)包括了回车所占的字符数( Windows 和 Linux 环境会不同)。
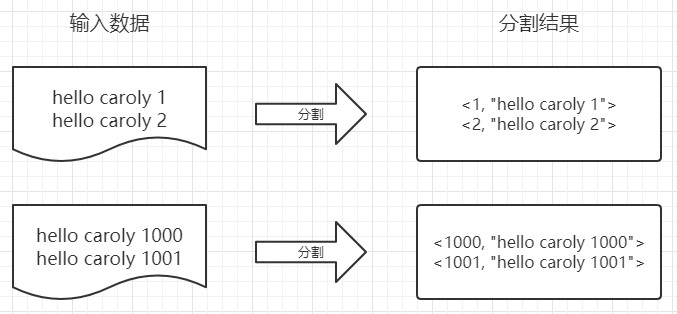
二、将分割好的 <key, value> 交给我们定义的 map 方法进行处理,生成新的 <key, value> 对。
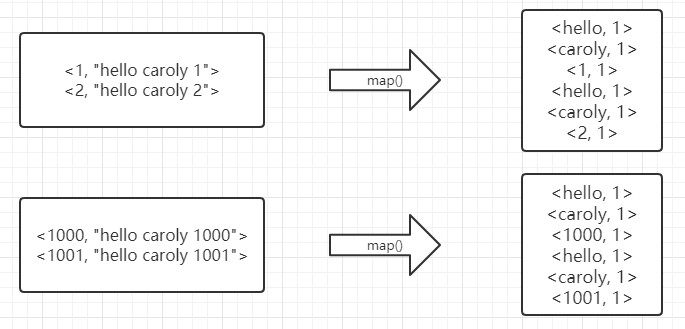
三、得到map方法输出的 <key, value> 对后,Mapper 会将它们按照 key 值进行排序,并执行 Combine 过程,将 key 值相同的的value累加,得到 Mapper 的最终输出结果。
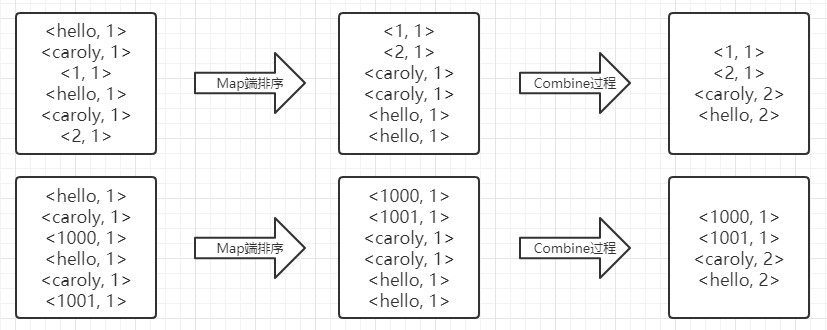
四、Reducer 先对从 Mapper 接收的数据进行排序,再交由我们自定义的 reduce 方法进行处理,得到新的 <key, value> 对,并作为 WordCount 的输出结果。

SQL操作
将数据文件放到『HDFS』上:
hdfs dfs -put wc /usr/
确保该目录下只有『wc』这一个文件。
创建两张表:
create external table wc
(
line string
)
location '/usr/';create table wc_result
(
word string,
ct int
);
第一张表存放原始数据,第二张表存放结果数据。
执行如下 SQL:
from (select explode(split(line,' ')) word from wc) t
insert into wc_result
select word,count(word) group by word;
首先进行切割操作,对字段『line』按照空格进行切割,会形成数组;使用『explode』转成一列;再从这个结果中进行查询并写入结果表。该操作走『MapReduce』。
最后查询一下结果表:
select * from wc_result;
本文由 caroly 创作,如果您觉得本文不错,请随意赞赏
采用 知识共享署名4.0 国际许可协议进行许可
本站文章除注明转载 / 出处外,均为本站原创或翻译,转载前请务必署名
原文链接:https://caroly.fun/archives/wordcount单词统计详解
最后更新:2021-04-29 16:03:15


