


分布式数据库(十一)
小注
容器化
容器化技术可以将资源虚拟化,从而更灵活快速地调配。容器镜像为应用打包提供了完美的解决方案,也为 DevOps 理念的落地扫清了技术障碍。可以说,容器已经成为现代软件工程化的基础设施,容器化已经成为一个不可逆的发展趋势。
Kubernetes 基本概念
1、Container
容器化就是将物理机划分为若干容器(Container),应用程序是直接部署在容器上的,并不会感知到物理机的存在。具体来说,这个容器就是 Docker,它使用的主要技术包括 Cgroup 和 Namespace。
Cgroup 是控制组群(Control Groups)的缩写,用来限制一个进程组能够使用的资源上限,包括 CPU、内存、磁盘、网络带宽等,本质上实现了资源的隔离。Namespace 修改了进程视图,使当前容器处于一个独立的进程空间,无法看到宿主机上的其他进程,本质上实现了权限上的隔离。这两项其实都是 Linux 平台上的成熟技术,甚至在 Docker 出现前已经被用在 Cloud Foundary 的 PaaS 平台上。
Docker 能够快速崛起的重要原因是,它通过容器镜像可以将文件系统与应用程序一起打包。这个文件系统是指操作系统所包含的文件、配置和目录。这样,就不会出现各种环境参数差异导致的错误,应用的部署变得非常容易,完美解决了应用打包的问题。
容器的本质是进程,但复杂的应用系统往往是一个进程组。如果为每个进程建立一个容器,那么容器间就有非常密切的交互关系,这样管理起来就更加复杂。
那么,有什么简化的办法吗?
Kubernetes 给出的答案就是 Pod。
2、Pod
在 Kubernetes 的设计中,最基本的管理单位是 Pod,而不是容器。
Pod 是 Kubernetes 在容器之上的一层封装,它由运行在同一主机上的一个或者多个容器构成。而且,同一个 Pod 中的容器可以共享一个 Network Namespace 和同一组数据卷,从而高效的信息交换。因为具有了这些特性,Pod 通常会被类比为物理机。
Pod 存在的意义还在于可以屏蔽容器之间可能存在依赖关系,这样做到 Pod 在拓扑关系上的完全对等,调度起来更加简单。
那么 Pod 又是如何被管理的呢?这就要说到 Kubernetes 的整体架构。
3、整体架构
总体上,Kubernetes 是一个主从结构(Master-Slave)。其中 Master 是一个控制面板,每个 Salve 就是物理节点上代理 Kubelet,Master 与 Kubelet 通讯完成对物理节点上 Pod 和 Container 的管理。外部网络可以直接通过节点上的 Proxy,调用容器中的服务,不需要经过 Master。
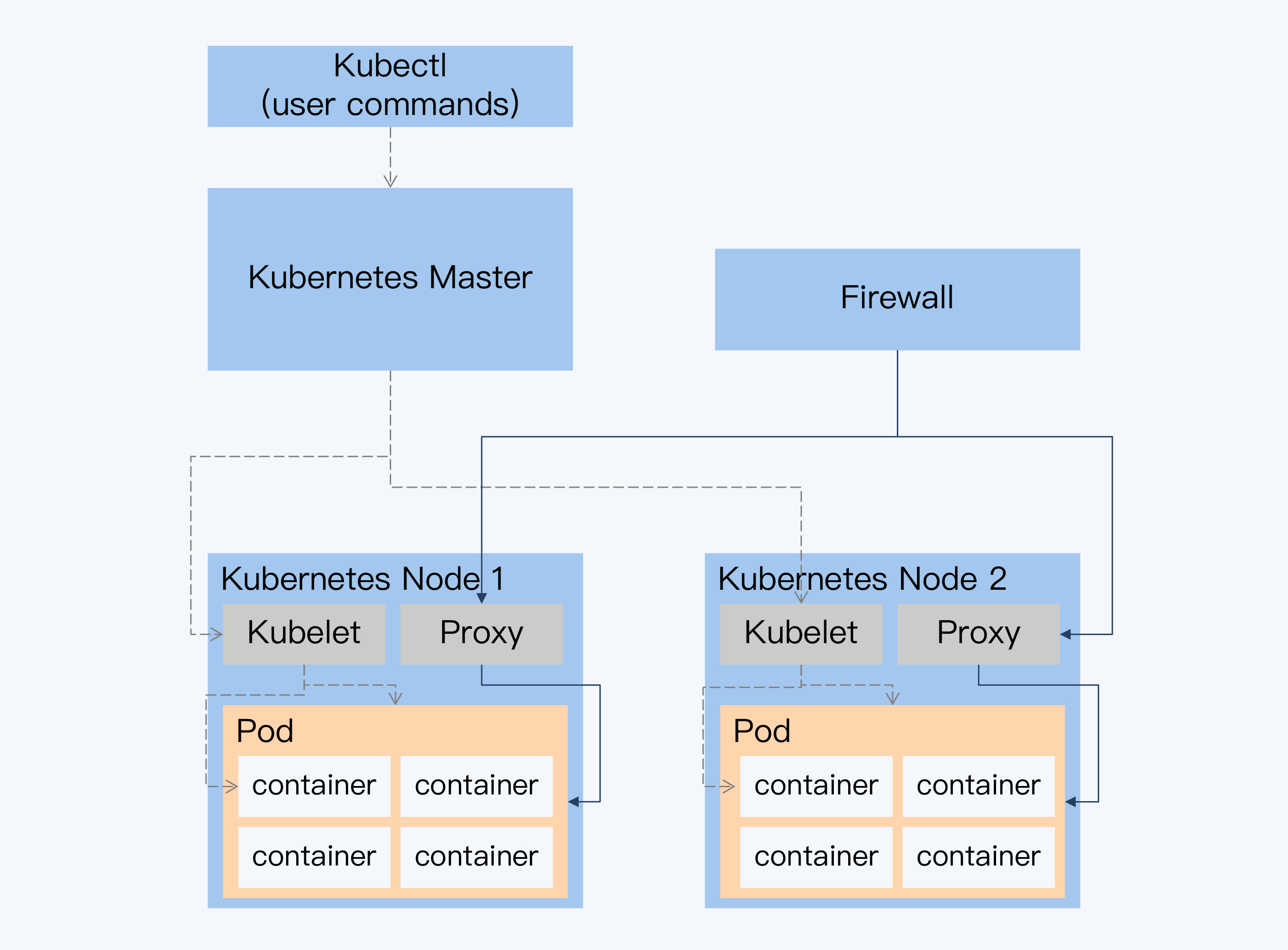
有状态服务(StatefulSet)
对于无状态服务的管理,用户可以定义好无状态服务的副本数量,Kubernetes 调度器就会在不同节点上启动多个 Pod,实现负载均衡和故障转移。多个副本对应的 Pod 是无差别的,所以在节点出现故障时,可以直接在新节点上启动新的 Pod 替换已经失效的 Pod。整个过程不涉及状态迁移问题,管理起来很简单。
但是,作为应用系统的基石,数据库和存储系统都是有状态服务。如果将它们排除在外,那容器化的价值将大打折扣。所以,Kubernetes 在 V1.3 版本开始推出 PetSet 用于管理有状态服务,并在 V1.5 版本更名为 StatefulSet。
通常,我们说数据库是一个有状态的服务,是指服务要依赖持久化数据,也就是存储状态。而对于 StatefulSet 来说,状态又分为两部分,除了存储状态,还有系统的拓扑状态。
拓扑状态
拓扑状态是指集群内节点之间的关系,在 Kubernetes 中就是 Pod 之间的关系。
对于应用服务器来说,因为它们互相之间是不感知、不依赖的,所以可以随意创建和销毁。但数据库就不一样了,即使是单体数据库,也会有主从复制的关系,从节点是依赖于主节点的。
而分布式数据库的节点角色更加复杂。除了 CockroachDB 这样的 P2P 架构,多数分布式数据库中的节点拓扑关系是不对等的,会明确的划分为计算节点、数据节点、元数据和全局时钟等。
拓扑状态管理的第一步是标识每个 Pod。我们已经知道,Pod 随时会被销毁、重建,而重建之后 IP 会发生变化,这将导致无法确定每个 Pod 的角色。StatefulSet 采用记录域名的方式,再通过 DNS 解析出 Pod 的 IP 地址。这样 Pod 就具有了稳定的网络标识。
同时,为了确保体现 Pod 之间的依赖关系,StatefulSet 还引入顺序的概念,将 Pod 的拓扑状态,也就是启动顺序,按照 Pod 的“名字 + 编号”的方式固定了下来。
存储状态
数据库的核心功能是存储,再来看看如何实现存储状态的管理。
早期版本中,提供了两种存储方式,分别是本地临时存储和远程存储。顾名思义,本地临时存储中的数据会随着 Pod 销毁而被清空,所以无法用做数据库的底层持久存储。
远程存储可以保证数据持久化,所以是一种可选方案。具体来说,就是使用持久化卷(Persistent Volume)作为数据的存储载体。当 Pod 进行迁移时,对应的 PV 也会重新挂载,而 PV 的底层实现是分布式文件系统,所以新的 Pod 仍然能访问之前保存的数据。

远程存储虽然可以使用,但是它与分布式数据库的架构设计理念存在很大冲突。分布式数据库都是采用本地磁盘存储的模式,并且对存储层做了很多针对性的优化。如果改为远程存储,这些设计将会失效,导致性能上有较大的损失。
事实上,这就是很多人反对数据库容器化部署的最主要的原因,数据密集型应用对 I/O 资源的消耗巨大,远程存储无法适应这个场景。
针对这个不足,Kubernetes 尝试引入本地持久卷(Local Persistent Volume)来解决。简单来说,就是一个 Local PV 对应一块本地磁盘。开启 Local PV 特性后,调度器会先获取所有节点与 Local PV 对应磁盘的关系,基于这些信息来调度 Pod。
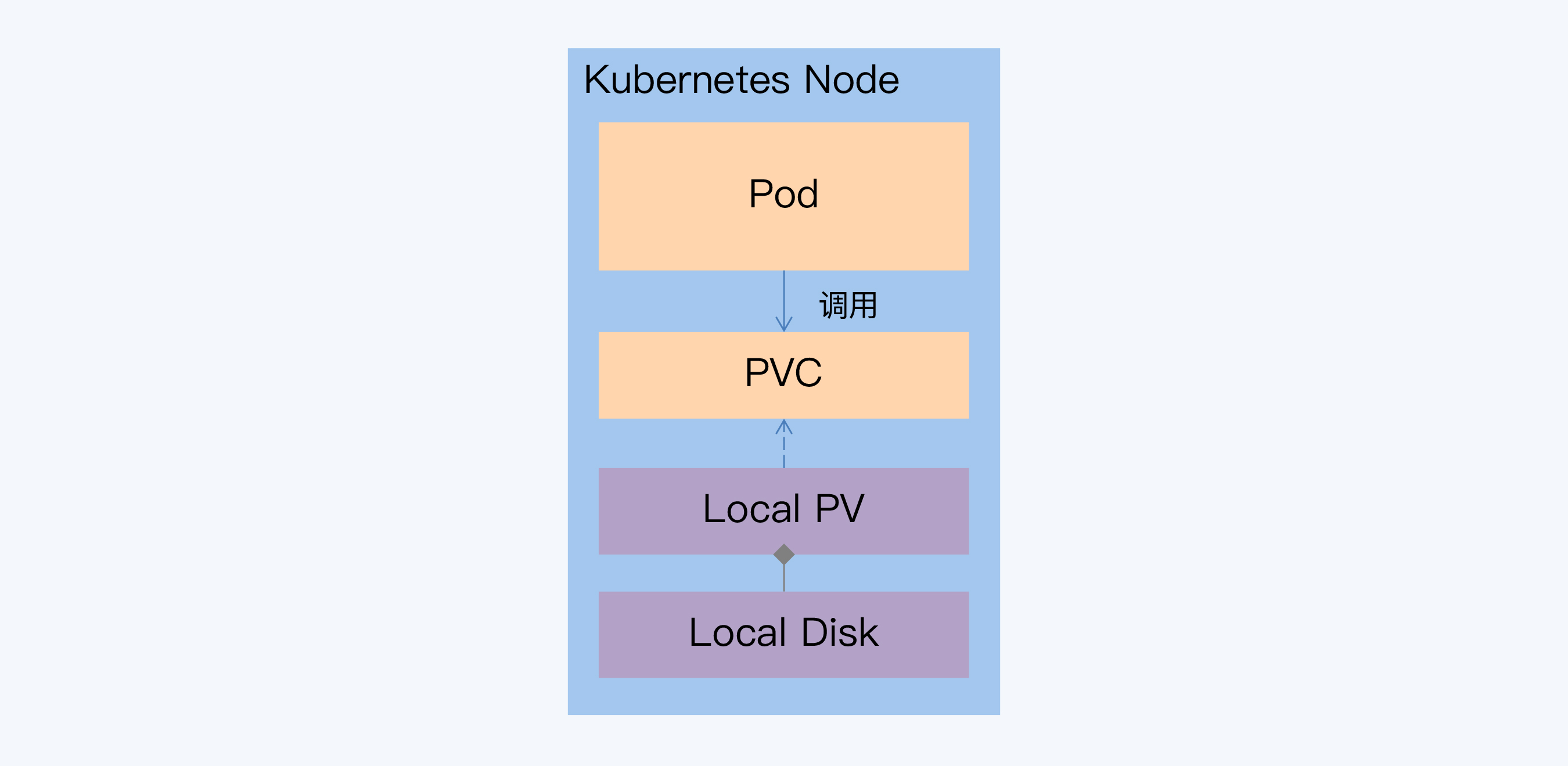
与普通 PV 不同,当挂载 Local PV 的节点宕机并无法恢复时,数据可能就会丢失。这和物理机部署方案面临的问题是一样的,而分布式数据库的多副本机制正好弥补了这一点。
不过 Local PV 推出得较晚,直到 V1.10(2018 年发布)Kubernetes 才相对稳定地支持调度功能,在 2019 年 3 月的 V1.14 中正式发布。
通过对拓扑状态和存储状态的管理,StatefulSet 初步解决了有状态服务的管理问题,但其中的一些关键特性(比如 Local PV)还不够成熟。另外,由于 Kubernetes 的抽象程度比较高,所以在真正实现分布式数据库的部署还需要很多复杂的控制。
Operator
控制逻辑的复杂性是与具体软件产品相关的,比如一个常见的问题就是对于 Pod 状态的判断。
Kubernetes 判断节点故障依据是每个节点上的 Kubelet 服务上报的节点状态。但是,Kubelet 作为一个独立的进程,从理论上说,它能否正常工作与用户应用并没有必然联系。那么就有可能出现,Kubelet 无法正常启动,但对应节点上的容器还可以正常运行。
这时,如果不处置原来的 Pod,立即在其他节点创建新的 Pod,应用系统可能就会出现异常。所以,调度过程还需要结合应用本身的状态来进行,其中的复杂性无法被统一封装,于是也就催生了一系列的 Operator。
Operator 的工作原理就是利用了 Kubernetes 的自定义资源,来描述用户期望的部署状态;然后在自定义控制器里,根据自定义 API 对象的变化,来完成具体的部署和运维工作。简单来说,Operator 就是将运维人员对软件操作的知识代码化。
etcd-operator 是最早出现的 Operator,用于实现 etcd 的容器部署。Operator 封装了有状态服务容器化的操作复杂性,对于应用系统上云的有重要的意义,有的分布式数据库厂商也开发了自己的 Operator,比如 TiDB 和 CockroachDB。
小结
- 容器可以更加精细的控制资源,并通过镜像功能实现应用打包部署,使开发、测试、生产等各个环境完美统一,因此得到了越来越广泛的使用。
- 容器是单进程模型,为了适应更复杂的应用,Kubernetes 又引入了 Pod 概念,一个 Pod 包含了同一节点上的多个容器。Kubernetes 通过调度管理 Pod 将复杂的应用系统快速容器化部署,这种技术称为『容器编排』。因为容器的本质是进程,所以 Kubernetes 也被成为下一代操作系统。
- Kubernetes 早期以支持无状态服务为主,Pod 完全对等,调度过程简单。为了适应更复杂的应用部署模式,Kubernetes 也在不断完善对有状态服务的支持,使用 StatefulSet 对象封装了相应的功能,包括拓扑状态管理和存储状态管理。在 1.14 版本中发布了本地持久化卷特性,增强了存储状态管理能力。
- 对于分布式系统来说,有状态服务的管理非常复杂,通过简单的 Kubelet 无法把握各个服务的真实状态,所以就有了 Operator 这个扩展方式,每个产品厂商可以拓展自定义控制器,进行更有针对性的管理。目前,Operator 的接受程度在不断提高,TiDB、CockroachDB 都开发了自己的 Operator。
加餐:资源调度是 Kubernetes 的一项核心功能,那么除了 Kubernetes 还有哪些集群资源调度系统?它们在设计上有什么差异吗?
随着很多基础系统向分布式架构过渡,集群资源调度成为一个非常广泛的需求,尤其是数据密集型系统。除 Kubernetes 外,知名度最高的可能就是 Yarn 和 Mesos,它们都是大数据生态体系下的工具。
Yarn 是 Hadoop 体系下的核心组件,被称为『数据操作系统』,所调度的资源单位和 Docker 有些相似,比如也使用了 Cgroup 隔离资源。Mesos 更是直接从大数据领域杀入容器编排领域,成为 Kubernetes 的直接竞争对手。
产品测试
无论是作为程序员还是架构师,都不会忽视测试的重要性,它贯穿于软件工程的整个生命周期,是软件质量的重要保障手段。
POC 的意思是概念验证,通常是指对客户具体应用的验证性测试。那验证性测试又具体要测些什么呢?对于数据密集型系统,很多企业的 POC 都会使用 TPC 基准测试。
TPC-C
TPC(Transaction Processing Performance Council),也就是国际事务性能委员会,是数十家会员公司参与的非盈利组织。它针对数据库不同的使用场景组织发布了多项测试标准,其中被业界广泛接受有 TPC-C 、TPC-H 和 TPC-DS。
这三个测试标准针对不同的细分场景。简单来说,TPC-C 针对 OLTP 场景;TPC-H 针对 OLAP 场景;而更晚些时候推出的 TPC-DS,在 TPC-H 的基础上又针对数据仓库的建模特点做了更新,并且在 2.0 版本中又增加对大数据技术的针对性测试。
这里说的分布式数据库主要服务于 OLTP 场景,所以重点关注 TPC-C。
TPC-C 发布的 标准规范 中,模拟了一家大型电子商务网站的日常业务。根据规范中的背景设定,这家公司的业务覆盖了很大的地理范围,所以设立了很多的仓库来支持邻近的销售区域,每个仓库都要维护 100,000 种商品的库存记录并支持 10 个销售区域,每个销售区域服务 3,000 个客户。

这个场景对应的数据库模型一共包含 9 张表,覆盖了订单创建、支付、订单状态查询、发货和检查库存等五种事务操作。客户会查询已经存在订单的状态或者下一个新的订单。平均每个订单有 10 个订单行(Order-Line),有 1% 订单行的商品在其对应的仓库中没有存货,必须由其他区域的仓库来供货。

可以看出,TPC-C 模拟的整个业务场景和我们日常使用的电子商务网站是非常相似的。所以说,TPC-C 测试场景是很有代表性的 OLTP 业务。
TPC-C 为数据库测试提供了一个开放的测试标准,很多 POC 甚至会直接套用这些数据模型和事务操作。可 POC 做起来真有这么容易吗?
TPC-C 的测试用例除了性能测试,也包含了事务一致性的测试,但实际测试中这部分往往会被忽略。这一方面是为了简化测试过程,另一方面是因为大家会觉得没有必要。既然这些产品都有不少实际案例了,那事务一致性应该就没问题了吧。
可是,对于分布式数据库来说,这真不是个简单的事情,甚至要更加严谨的技术手段来证明。事务一致性方面比 TPC-C 更权威的测试标准是 Jepsen。
Jepsen
Jepsen 是一个开源的分布式一致性验证框架,专门用来测试分布式存储系统,比如分布式数据库、分布式键值系统和分布式消息队列等等。
Jepsen 曾经对很多知名的分布式存储系统进行了测试,而且往往都会发现一些问题,其中分布式数据库就包括 CockroachDB、YugabyteDB、TiDB、VoltDB 和 FaunaDB 等。以下是摘自 Jepsen 官网 的所有测试系统列表。
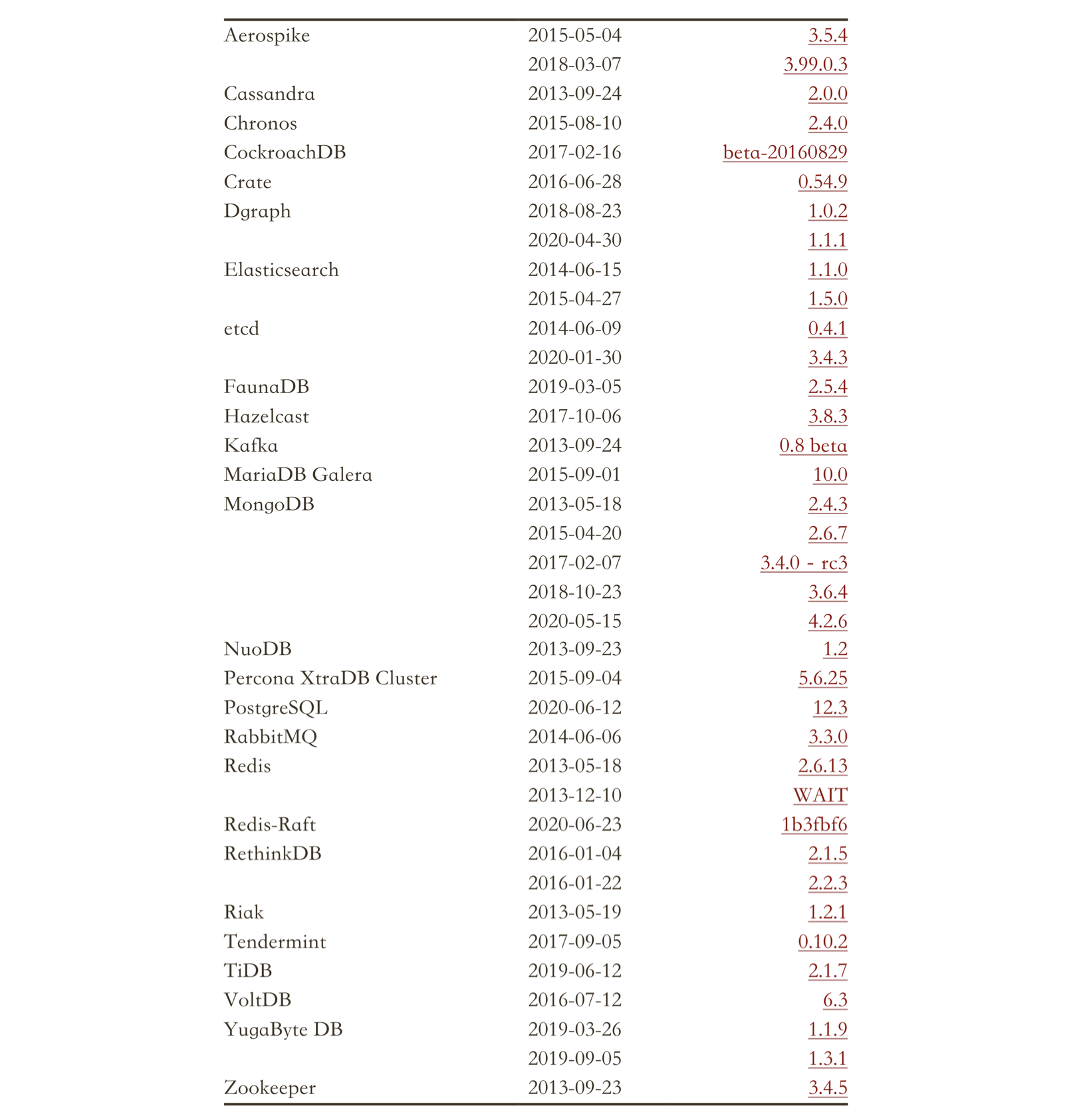
要知道这些测试并不是 Jepsen 单方面开展的,而都是和产品团队共同协作完成的,并且这些产品厂商还要向 Jepsen 支付费用。由此可见,Jepsen 在分布式系统测试方面,已经具有一定的权威性。
作为开源软件,可以从 Github 上下载到 Jepsen 的源码,所以有些厂商就在它的基础上定制自己的测试系统。但是比较遗憾的是,Jepsen 的作者选择了一种小众的开发语言 Clojure。我猜,这给多数程序员带来了障碍,因为我能想到的 Clojure 项目似乎只有 Storm。
这里,简单介绍下 Jepsen 的架构。
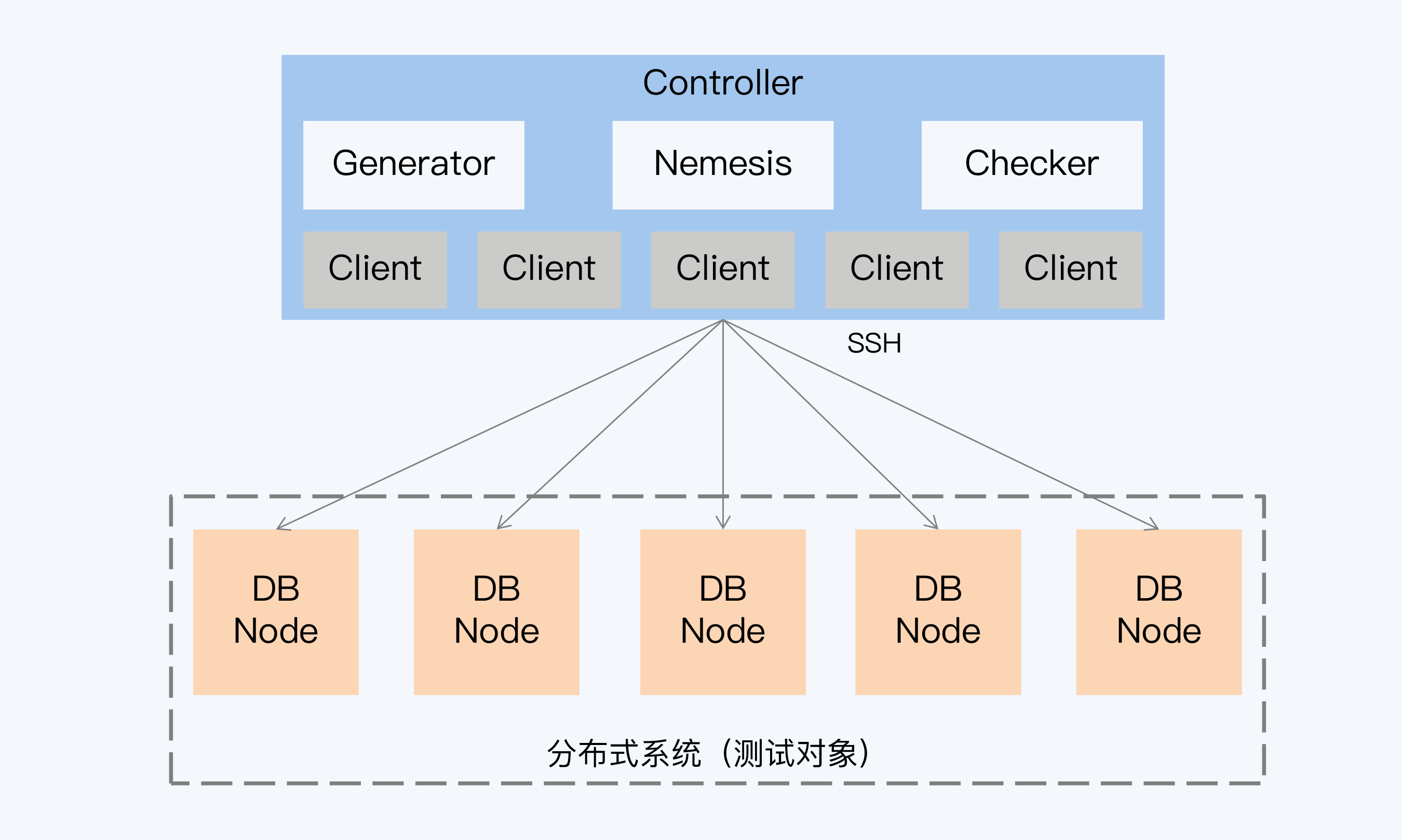
按照 Jepsen 的推荐方案,被测试的分布式系统通常部署在 5 个节点上,而 Jepsen 的程序主要部署在另外的控制节点上。这个控制节点会初始化若干个进程作为分布式系统的访问客户端,当然这里也包括了分布式系统提供的客户端代码。
测试过程中,控制节点要完成三项工作,第一是通过 Generator 生成每个客户端的操作,第二是通过 Nemesis 实现故障注入,最后使用 Checker 分析每个客户端的操作记录来验证一致性。
在整个测试框架中,Nemesis 是特别重要的部分,这是因为 Jepsen 的核心逻辑就是要在各种错误情况下,检测分布式系统还能否正常运行。
『故障注入』在普通测试中并不常见,这里的故障是特指网络分区、时钟不同步这样的底层基础设施层面的问题。因为分布式系统的架构复杂,节点间有千丝万缕的联系,任何软硬件基础设施的错误都可能造成不可收拾的后果,但业务逻辑层面的测试用例又无法覆盖这类场景,所以要靠 Jepsen 来填补这块空白。
既然故障注入这么重要,那么 Jepsen 注入的这些故障就够了吗?是不是要按照自己的业务场景增加一些故障呢?这就要说一下混沌工程的概念了。
混沌工程
混沌工程(Chaos Engineering)最早是由 Netflix 工程师提出来的。他们给出了这样的定义:混沌工程是在分布式系统上进行实验的学科, 旨在提升系统的容错性,建立对系统抵御生产环境中发生不可预知问题的信心。
可以从三个层面来理解这个定义。
1、复杂性
首先,分布式系统的复杂性是混沌工程产生的基础。相比传统的单体系统,分布式系统中包含更多硬件设备,多样化的服务和复杂交互机制。这些因素单独来看似乎是可控的,也有完备的异常处置手段,但当它们组合在一起就会相互影响从而引发不可预知的结果,导致故障发生。而人力是不可能完全阻止这些故障。
混沌工程就是在这些故障发生前,尽可能多的识别出导致这些异常的因素,主动找出系统脆弱环节的方法学。
2、实验
第二关键点是实验。混沌工程与单纯的故障注入是有区别的,混沌工程的输入是尝试性,目的是探索更多可能发生的奇怪场景,促使正常情况下不可预测的事情发生,从而确认系统的稳定性。我想,正是因为结果具有很大的不确定性,这个过程才会称为『实验』。
最早的混沌测试工具是 Netflix 的 Chaos Monkey,它只会注入一种混乱,那就是随机杀死节点。后来逐步发展,混沌测试框架引入的故障越来越多,包括模拟网络通讯延迟、磁盘故障、CPU 负载过高等等。而混沌测试的观察对象也不仅是一致性(像 Jepsen 那样),而是从系统的各个维度上定义一系列稳态指标,观察混乱注入后系统是否能够快速恢复。
3、生产环境
第三点,也是混沌工程非常核心的理念,混沌实验在生产环境进行才会获得更大的价值,因为这样才能真正建立起信心,相信系统能抵御各种故障。不过,这个理念也有一定的争议。比如,你今天坐飞机出差,这时混沌工程师要在飞机的控制系统上注入一些故障,想看看系统会不会崩溃,你能接受吗?我想,正常人都会拒绝吧。
目前,一些分布式数据库也应用混沌工程进行系统测试,例如 GoldenDB、CockroachDB 和 TiDB。
TLA
Leslie Lamport 提出的 TLA(Temporal Logical of Actions,行为时态逻辑),是使用数理逻辑来描述系统的时序状态,并验证程序的正确性。
1994 年 Lamport 发表了 同名论文。1999 年 Lamport 又发表 "Specifying Concurrent Systems with TLA+" 论文,提出了 TLA+。TLA+ 是一种软件建模语言,再加上配套的模型校验工具 TLC,这样我们就可以像写程序一样编写 TLA,可以运行来验证最终结果的。2002 年 Lamport 又发布了一本完整的 TLA+ 教科书 Specifying Systems: The TLA+ Language and Tools for Software Engineers。因为 TLA+ 使用的是数学化的表达方式,对程序员并不友好,所以后来又出现了 PlusCal。它比 TLA+ 更接近于编程语言,写好的代码可以很方便的转换成 TLA+ 并使用 TLA+ 的模型验证。
小结
- TPC-C 是国际事务性能委员会针对 OLTP 数据库建立的一套测试规范,也是目前广泛接受的测试基准。在很多企业的 POC 测试中会引入 TPC-C,但是由于 TPC-C 的开放性,有的产品会进行针对性优化,使得最终的评测指标失真。要能够分辨优化手段是否对你的业务有普适性,还需要对产品架构的深入掌握。
- Jepsen 是针对分布式存储系统,进行数据一致性和事务一致性测试的工具。目前已经测试了很多知名系统,具有一定的权威性。Jepsen 通过故障注入的方式进行测试,会覆盖很多在普通测试不能发现的场景。
- 混沌工程是针对分布式系统提出的方法学。它和测试一样都是为了提高系统的可用性和稳定性,以故障注入为主要手段。混沌工程并不仅是针对某个具体分布式系统提出的。它强调在生产环境注入故障,在受控的范围内观测系统,体现了反脆弱的思想。总之,混沌工程试图从企业整体运维的视角,用截然不同的理念来提升系统的可用性。
- 所有的测试方法都只能发现问题,但无法证明正确性。形式化验证可以完美解决这问题,并在很多硬件设计领域有落地实践。Lamport 提出的 TLA 将形式化验证引入软件工程,使用数学工具定义程序逻辑,从而可以达到证明软件无 Bug 的目标。经过不断完善,TLA 从模型到语言、工具建立了一套完备的机制,很多企业也开始使用 TLA 证明关键设计逻辑的正确性。
加餐:除了分布式数据库,对于其他类型的分布式存储系统,你知道有哪些主流的测试工具吗?
由于分布式系统的复杂性,测试工具就显得更加重要。除数据库外,比较典型是针对分布式键值系统的测试工具,例如 YCSB。YCSB(Yahoo! Cloud Serving Benchmark)是一个开源的测试框架,你可以从 Github 上下载到源码。
YCSB 支持几乎所有的主流分布式键值系统,包含 HBase、Redis、Cassandra 和 BigTable 等。YCSB 支持典型的 PUT\GET\SCAN 操作,可以很容易地在它的基础上扩展,增加对其他键值系统的支持。
学习资料
GitHub: jepsen
Jepsen: Analyses
Leslie Lamport: A Temporal Logic of Actions
Leslie Lamport: Specifying Concurrent Systems with TLA+
Leslie Lamport: Specifying Systems: The TLA+ Language and Tools for Software Engineers
Transaction Processing Performance Council: TPC BENCHMARK™ C:Standard Specification (Revision 5.11)
更新时间:2022-02-07 13:33:50
本文由 caroly 创作,如果您觉得本文不错,请随意赞赏
采用 知识共享署名4.0 国际许可协议进行许可
本站文章除注明转载 / 出处外,均为本站原创或翻译,转载前请务必署名
原文链接:https://caroly.fun/archives/分布式数据库十一
最后更新:2022-02-07 13:33:50

