


分布式数据库(四)
小注
隔离性(显式读写冲突)
多版本并发控制(Multi-Version Concurrency Control,MVCC)就是 通过记录数据项历史版本的方式,来提升系统应对多事务访问的并发处理能力。今天,几乎所有主流的单体数据库都实现了 MVCC,它已经成为一项非常重要也非常普及的技术。
MVCC 出现前,读写操作之间是互斥的,具体是通过锁机制来实现的。示例如下:

图中事务 T1、T2 先后启动,分别对数据库执行写操作和读操作。写操作是一个过程,在过程中任意一点,数据的变更都是不完整的,所以 T2 必须在数据写入完成后才能读取,也就形成了读写阻塞。反之,如果 T2 先启动,T1 也要等待 T2 将数据完全读取后,才能执行写入。
如果先执行的是 T1 写事务,除了磁盘写入数据的时间,由于要保证数据库的高可靠,至少还有一个备库同步复制主库的变更内容。这样,阻塞时间就要再加上一次网络通讯的开销。
如果先执行的是 T2 只读事务,虽然不用考虑复制问题,但是读操作通常会涉及更大范围的数据,这样一来加锁的记录会更多,被阻塞的写操作也就更多。而且,只读事务往往要执行更加复杂的计算,阻塞的时间也就更长。
所以说,用锁解决读写冲突问题,带来的事务阻塞开销还是不小的。相比之下,用 MVCC 来解决读写冲突,就不存在阻塞问题,要优雅得多了。
MVCC 的设计随架构风格不同而不同。在 PGXC 架构中,因为数据节点就是单体数据库,所以 PGXC 的 MVCC 实现方式其实就是单体数据库的实现方式。
单体数据库的 MVCC
MVCC 要记录数据的历史版本,这就涉及到存储的问题。
MVCC 的存储方式
MVCC 有三类存储方式,一类是将历史版本直接存在数据表中的,称为 Append-Only,典型代表是 PostgreSQL。另外两类都是在独立的表空间存储历史版本,它们区别在于存储的方式是全量还是增量。增量存储就是只存储与版本间变更的部分,这种方式称为 Delta,也就是数学中常作为增量符号的那个 Delta,典型代表是 MySQL 和 Oracle。全量存储则是将每个版本的数据全部存储下来,这种方式称为 Time-Travle,典型代表是 HANA。

每种方式都有一定的优缺点:
Append-Only 方式
优点:
- 在事务包含大量更新操作时也能保持较高效率。因为更新操作被转换为 Delete + Insert,数据并未被迁移,只是有当前版本被标记为历史版本,磁盘操作的开销较小。
- 可以追溯更多的历史版本,不必担心回滚段被用完。
- 因为执行更新操作时,历史版本仍然留在数据表中,所以如果出现问题,事务能够快速完成回滚操作。
缺点:
- 新老数据放在一起,会增加磁盘寻址的开销,随着历史版本增多,会导致查询速度变慢。
Delta 方式
优点:
- 因为历史版本独立存储,所以不会影响当前读的执行效率。
- 因为存储的只是变化的增量部分,所以占用存储空间较小。
缺点:
- 历史版本存储在回滚段中,而回滚段由所有事务共享,并且还是循环使用的。如果一个事务执行持续的时间较长,历史版本可能会被其他数据覆盖,无法查询。
- 这个模式下读取的历史版本,实际上是基于当前版本和多个增量版本计算追溯回来的,那么计算开销自然就比较大。
Oracle 早期版本中经常会出现的 ORA-01555 『快照过旧』(Snapshot Too Old),就是回滚段中的历史版本被覆盖造成的。通常,设置更大的回滚段和缩短事务执行时间可以解决这个问题。随着 Oracle 后续版本采用自动管理回滚段的设计,这个问题也得到了缓解。
Time-Travel 方式
优点:
- 同样是将历史版本独立存储,所以不会影响当前读的执行效率。
- 相对 Delta 方式,历史版本是全量独立存储的,直接访问即可,计算开销小。
缺点:
- 相对 Delta 方式,需要占用更大的存储空间。
当然,无论采用三种存储方式中的哪一种,都需要进行历史版本清理。

MVCC 的工作过程
历史版本存储下来要解决多事务的并发控制问题,也就是保证事务的隔离性。隔离性的多个级别中,可接受的最低隔离级别就是『已提交读』(Read Committed,RC)。
先来看 RC 隔离级别下 MVCC 的工作过程。
- 当前事务更新所产生的数据。
- 当前事务启动前,已经提交事务更新的数据。
用一个例子来说明:

T1 到 T7 是七个数据库事务,它们先后运行,分别操作数据库表的记录 R1 到 R7。事务 T6 要读取 R1 到 R6 这六条记录,在 T6 启动时(T6-1)会向系统申请一个活动事务列表,活动事务就是已经启动但尚未提交的事务,这个列表中会看到 T3、T4、T5 等三个事务。
T6 查询到 R3、R4、R5 时,看到它们最新版本的事务 ID 刚好在活动事务列表里,就会读取它们的上一版本。而 R1、R2 最新版本的事务 ID 小于活动事务列表中的最小事务 ID(即 T3),所以 T6 可以看到 R1、R2 的最新版本。
这个例子中 MVCC 的收益非常明显,T6 不会被正在执行写入操作的三个事务阻塞,而如果按照原来的锁方式,T6 要在 T3、T4、T5 三个事务都结束后,才能执行。
快照的工作原理
MVCC 在 RC 级别的效果还不错。那么,如果隔离级别是更严格一些的『可重复读』(RR)呢?
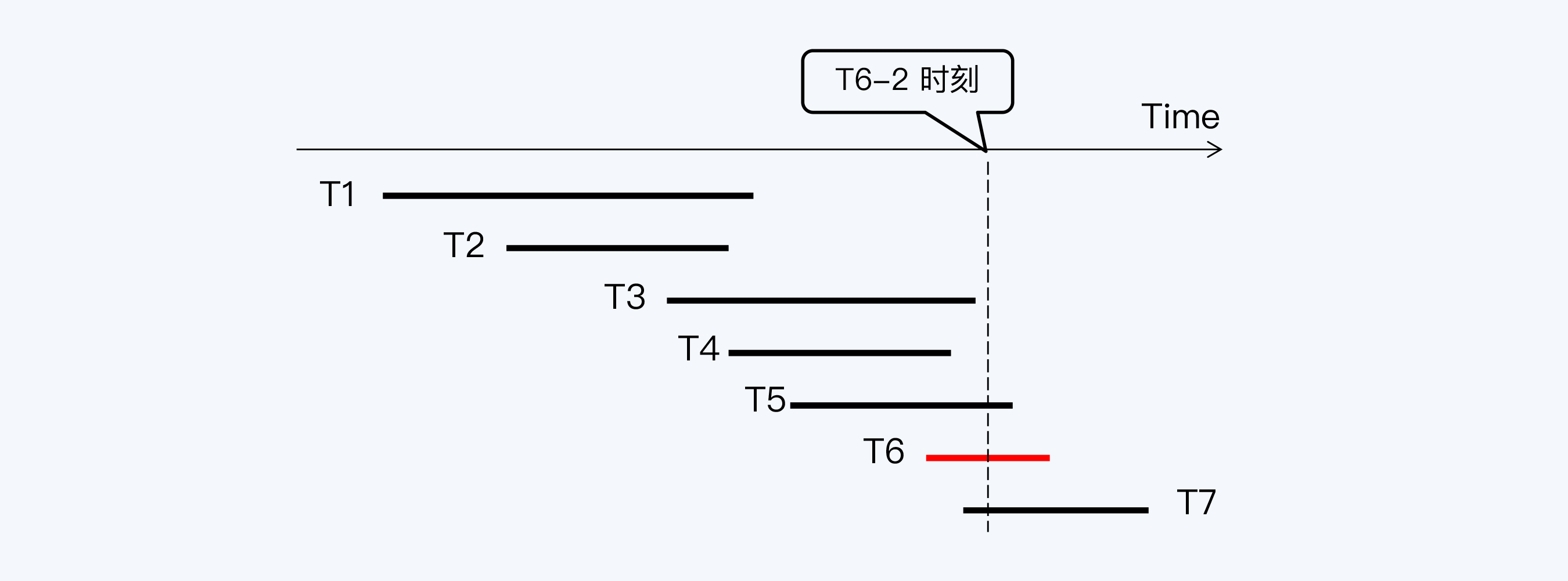
当 T6 执行到下一个时间点(T6-2),T1 到 T4 等 4 个事务都已经提交,此时 T6 再次向系统申请活动事务列表,列表包含 T5 和 T7。遵循同样的规则,这次 T6 可以看到 R1 到 R4 等四条记录的最新版本,同时看到 R5 的上一版本。
很明显,T6 刚才和现在这两次查询得到了不同的结果集,这是不符合 RR 要求的。
实现 RR 的办法也很简单,我们只需要记录下 T6-1 时刻的活动事务列表,在 T6-2 时再次使用就行了。那么,这个反复使用的活动事务列表就被称为『快照』(Snapshot)。

快照是基于 MVCC 实现的一个重要功能,从效果上看, 快照就是快速地给数据库拍照片,数据库会停留在你拍照的那一刻。所以,用『快照』来实现 RR 是很方便的。
从上面的例子可以发现,RC 与 RR 的区别在于 RC 下每个 SQL 语句会有一个自己的快照,所以看到的数据库是不同的,而 RR 下,所有 SQL 语句使用同一个快照,所以会看到同样的数据库。
为了提升效率,快照不是单纯的事务 ID 列表,它会统计最小活动事务 ID,还有最大已提交事务 ID。这样,多数事务 ID 通过比较边界值就能被快速排除掉,如果事务 ID 恰好在边界范围内,再进一步查找是否与活跃事务 ID 匹配。
快照在 MySQL 中称为 ReadView,在 PostgreSQL 中称为 SnapshotData,组织方式都是类似的。
PGXC 读写冲突处理
在 PGXC 架构中,实现 RC 隔离级的处理过程与单体数据库差异并不大。PGXC 在实现 RR 时遇到两个挑战,也就是实现快照的两个挑战。
-
一是如何保证产生单调递增事务 ID。每个数据节点自行处理显然不行,这就需要由一个集中点来统一生成。
-
二是如何提供全局快照。每个事务要把自己的状态发送给一个集中点,由它维护一个全局事务列表,并向所有事务提供快照。
所以,PGXC 风格的分布式数据库都有这样一个集中点,通常称为全局事务管理器(GTM)。又因为事务 ID 是单调递增的,用来衡量事务发生的先后顺序,和时间戳作用相近,所以全局事务管理器也被称为『全局时钟』。
NewSQL 读写冲突处理
这里主要介绍 TiDB 和 CockroachDB 两种实现方式,因为它们是比较典型的两种情况。
TiDB

TiDB 底层是分布式键值系统,假设两个事务操作同一个数据项。其中,事务 T1 执行写操作,由 Prewrite 和 Commit 两个阶段构成,对应了之前描述的两阶段提交协议(2PC)。这里也可以简单理解为 T1 的写操作分成了两个阶段,T2 在这两个阶段之间试图执行读操作,但是 T2 会被阻塞,直到 T1 完成后,T2 才能继续执行。
TiDB 为什么没有使用快照读取历史版本呢? TiDB 官方文档并没有说明背后的思路,猜测问题出在全局事务列表上,因为 TiDB 根本没有设计全局事务列表。当然这应该不是设计上的疏忽,可以把它理解为一种权衡,是在读写效率和全局事务列表的维护代价之间的选择。
事实上,PGXC 中的全局事务管理器就是一个单点,很容易成为性能的瓶颈,而分布式系统一个普遍的设计思想就是要避免对单点的依赖。当然,TiDB 的这个设计付出的代价也是巨大的。虽然,TiDB 在 3.0 版本后增加了悲观锁,设计稍有变化,但大体仍是这样。
CockroachDB
CockroachDB 设计了一张全局事务列表,但它不是照搬了单体数据库的『快照』。

依旧是 T1 事务先执行写操作,中途 T2 事务启动,执行读操作,此时 T2 会被优先执行。待 T2 完成后,T1 事务被重启。重启的意思是 T1 获得一个新的时间戳(等同于事务 ID)并重新执行。
这里还是会产生读写阻塞,Why?
CockroachDB 没有使用快照,不是因为没有全局事务列表,而是因为它的隔离级别目标不是 RR,而是 SSI,也就是可串行化。
对于串行化操作来说,没有与读写并行操作等价的处理方式,因为先读后写和先写后读,读操作必然得到两个不同结果。更加学术的解释是:先读后写操作会产生一个 读写反向依赖,可能影响串行化事务调度。
在上面的例子中,为了方便描述,简化了读写冲突的处理过程。事实上,被重启的事务并不一定是执行写操作的事务。CockroachDB 的每个事务都有一个优先级,出现事务冲突时会比较两个事务的优先级,高优先级的事务继续执行,低优先级的事务则被重启。而被重启事务的优先级也会提升,避免总是在竞争中失败,最终被『饿死』。
小结
- 用锁机制来处理读写冲突会影响并发处理能力,而 MVCC 的出现很好地解决了这个问题,几乎所有的单体数据库都实现了 MVCC。MVCC 技术包括数据的历史版本存储、清理机制,存储方式具体包括 Append-Only、Delta、Time-Travel 三种方式。通过 MVCC 和快照(基于 MVCC),单体数据库可以完美地解决 RC 和 RR 级别下的读写冲突问题,不会造成事务阻塞。
- PGXC 风格的分布式数据库,用单体数据库作为数据节点存储数据,所以自然延续了其 MVCC 的实现方式。但 PGXC 的改变在于增加了全局事务管理器统一管理事务 ID 的生成和活动事务列表的维护。
- NewSQL 风格的分布式数据库,没有普遍采用快照解决读写冲突问题,其中 TiDB 是由于权衡全局事务列表的代价,CockroachDB 则是因为要实现更高的隔离级别。但无论哪种原因,都造成了读写并行能力的下降。
要特别说明的是,虽然 NewSQL 架构的分布式数据库没有普遍使用快照处理读写事务,但它们仍然实现了 MVCC,在数据存储层保留了历史版本。所以,NewSQL 产品往往也会提供一些低数据一致性的只读事务接口,提升读取操作的性能。
隔离性(隐式读写冲突)
关于时间,我们得接受一个事实,那就是无法在工程层面得到绝对准确的时间。其实,任何度量标准都没有绝对意义上的准确,这是因为量具本身就是有误差的,时间、长度、重量都是这样的。
不确定时间窗口
时间会带来什么问题,用下图说明:

图中共有 7 个数据库事务,T1 到 T7,其中 T6 是读事务,其他都是写事务。事务 T2 结束的时间点(记为 T2-C)早于事务 T6 启动的时间点(记为 T6-S),这是基于数据记录上的时间戳得出的判断,但实际上这个判断很可能是错的。

这是因为时间误差的存在,T2-C 时间点附近会形成一个不确定时间窗口,也称为置信区间或可信区间。严格来说,我们只能确定 T2-C 在这个时间窗口内,但无法更准确地判断具体时间点。同样,T6-S 也只是一个时间窗口。时间误差不能消除,但可以通过工程方式控制在一定范围内,例如在 Spanner 中这个不确定时间窗口(记为 ɛ)最大不超过 7 毫秒,平均是 4 毫秒。
当我们还原两个时间窗口后,发现两者存在重叠,所以无法判断 T2-C 与 T6-S 的先后关系。只有避免时间窗口出现重叠。『waiting out the uncertainty』,用等待来消除不确定性。
在实践中,有两种方式可供选择:写等待 和 读等待。
写等待:Spanner
Spanner 选择了写等待方式,更准确地说是用提交等待(commit-wait)来消除不确定性。
Spanner 是直接将时间误差暴露出来的,所以调用当前时间函数 TT.now() 时,会获得的是一个区间对象 TTinterval。它的两个边界值 earliest 和 latest 分别代表了最早可能时间和最晚可能时间,而绝对时间就在这两者之间。另外,Spanner 还提供了 TT.before() 和 TT.after() 作为辅助函数,其中 TT.after() 用于判断当前时间是否晚于指定时间。
理论等待时间
对于一个绝对时间点 S,至少需要等到 S + ɛ 时刻 TT.after(S) 才为真,这个 ɛ 就是不确定时间窗口的宽度。如下图所示:

从直觉上说,标识数据版本的『提交时间戳』和事务的真实提交时间应该是一个时间。那么就有如下过程:有当前事务 Ta,已经获得了一个绝对时间 S 作为『提交时间戳』。Ta 在 S 时刻写盘,保存的时间戳也是 S。事务 Tb 在 Ta 结束后的 S + X 时刻启动,获得时间区间的最小值是 TT1.earliest。如果 X 小于时间区间 ɛ,则 TT1.earliest 就会小于 S,那么 Tb 就无法读取到 Ta 写入的数据。
Tb 在 Ta 提交后启动却读取不到 Ta 写入的数据,这显然不符合线性一致性的要求。

写等待的处理方式是这样的。事务 Ta 在获得『提交时间戳』S 后,再等待 ɛ 时间后才写盘并提交事务。真正的提交时间是晚于『提交时间戳』的,中间这段时间就是等待。这样 Tb 事务启动后,能够得到的最早时间 TT2.earliet 肯定不会早于 S 时刻,所以 Tb 就一定能够读取到 Ta。这样就符合线性一致性的要求了。
综上,事务获得『提交时间戳』后必须等待 ɛ 时间才能写入磁盘,即 commit-wait。
但是 Spanner 拿不到绝对时间 S,会有误差。
实际等待时间
Spanner 将含有写操作的事务定义为读写事务。读写事务的写操作会以两阶段提交(2PC)的方式执行。
2PC 的第一阶段是预备阶段,每个参与者都会获取一个『预备时间戳』,与数据一起写入日志。第二阶段,协调节点写入日志时需要一个『提交时间戳』,而它必须要大于任何参与者的『预备时间戳』。所以,协调节点调用 TT.now() 函数后,要取该时间区间的 lastest 值(记为 s),而且 s 必须大于所有参与者的『预备时间戳』,作为『提交时间戳』。
这样,事务从拿到提交时间戳到 TT.after(s) 为 true,实际等待了两个单位的时间误差。如下图所示。

针对同一个数据项,事务 T8 和 T9 分别对进行写入和读取操作。T8 在绝对时间 100ms 的时候,调用 TT.now() 函数,得到一个时间区间 [99,103],选择最大值 103 作为提交时间戳,而后等待 8 毫秒(即 2ɛ)后提交。
这样,无论如何 T9 事务启动时间都晚于 T8 的“提交时间戳”,也就能读取到 T8 的更新。
这个过程中,第一个时间差是 2PC 带来的,如果换成其他事务模型也许可以避免,而第二个时间差是真正的 commit-wait,来自时间的不确定性,是不能避免的。
TrueTime 的平均误差是 4 毫秒,commit-wait 需要等待两个周期,那 Spanner 读写事务的平均延迟必然大于等于 8 毫秒。为啥有人会说 Spanner 的 TPS 是 125 呢?原因就是这个。其实,这只是事务操作数据出现重叠时的吞吐量,而无关的读写事务是可以并行处理的。
读等待:CockroachDB
读等待的代表产品是 CockroachDB。
因为 CockroachDB 采用混合逻辑时钟(HLC),所以对于没有直接关联的事务,只能用物理时钟比较先后关系。CockroachDB 各节点的物理时钟使用 NTP 机制同步,误差在几十至几百毫秒之间,用户可以基于网络情况通过参数『maximum clock offset』设置这个误差,默认配置是 250 毫秒。
写等待模式下,所有包含写操作的事务都受到影响,要延后提交;而读等待只在特殊条件下才被触发,影响的范围要小得多。用以下例子说明:
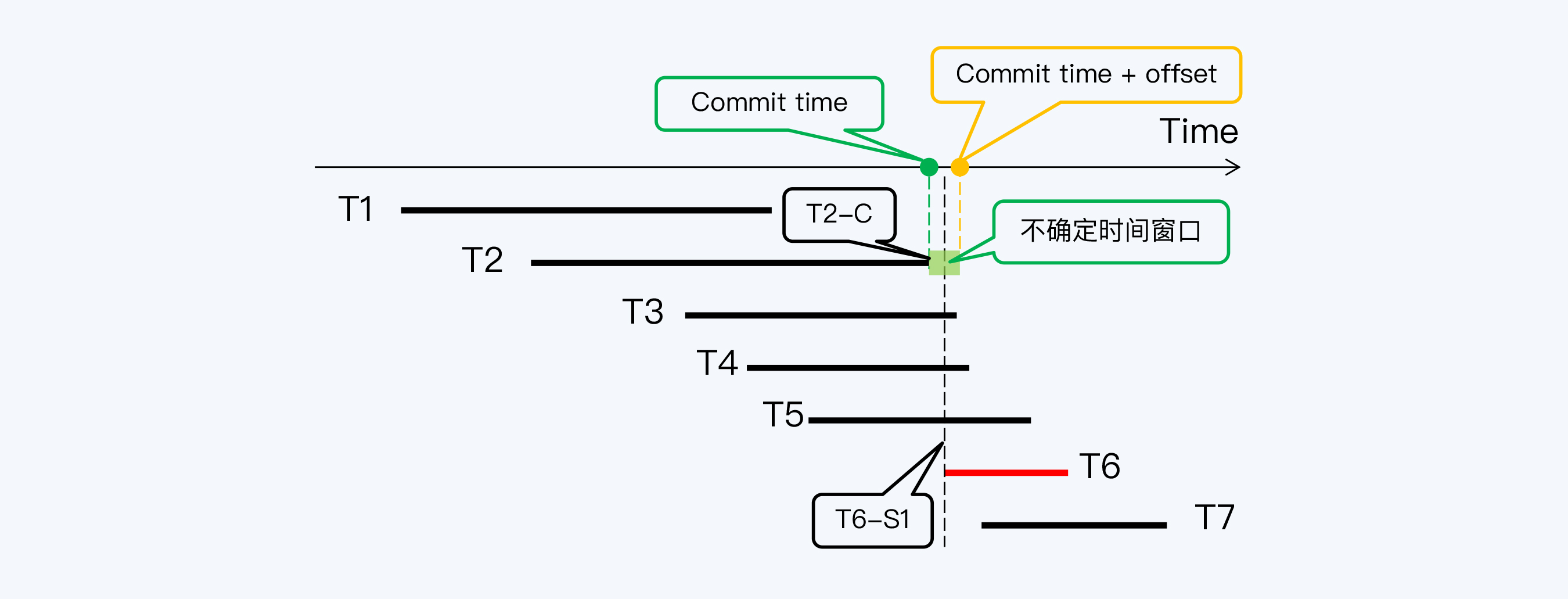
事务 T6 启动获得了一个时间戳 T6-S1,此时虽然事务 T2 已经在 T2-C 提交,但 T2-C 与 T6-S1 的间隔小于集群的时间偏移量,所以无法判断 T6 的提交是否真的早于 T2。

这时,CockroachDB 的办法是重启(Restart)读操作的事务,就是让 T6 获得一个更晚的时间戳 T6-S2,使得 T6-S2 与 T2-C 的间隔大于 offset,那么就能读取 T2 的写入了。

不过,接下来又出现更复杂的情况, T6-S2 与 T3 的提交时间戳 T3-C 间隔太近,又落入了 T3 的不确定时间窗口,所以 T6 事务还需要再次重启。而 T3 之后,T6 还要重启越过 T4 的不确定时间窗口。

最后,当 T6 拿到时间戳 T6-S4 后,终于跳过了所有不确定时间窗口,读等待过程到此结束,T6 可以正式开始它的工作了。
在这个过程中,可以看到读等待的两个特点:一是偶发,只有当读操作与已提交事务间隔小于设置的时间误差时才会发生;二是等待时间的更长,因为事务在重启后可能落入下一个不确定时间窗口,所以也许需要经过多次重启。
Spanner 采用了写等待方案,也就是 Commit Wait,理论上每个写事务都要等待一个时间置信区间。对 Spanner 来说这个区间最大是 7 毫秒,均值是 4 毫秒。但是,由于 Spanner 的 2PC 设计,需要再增加一个时间置信区间,来确保提交时间戳晚于预备时间戳。所以,实际上 Spanner 的写等待时间就是两倍时间置信区间,均值达到了 8 毫秒。传说中,Spanner 的 TPS 是 125 就是用这个均值计算的(1 秒 /8 毫秒),但如果事务之间操作的数据不重叠,其实是不受这个限制的。
CockroachDB 采用了读等待方式,就是在所有的读操作执行前处理时间置信区间。读等待的优点是偶发,只有读操作落入写操作的置信区间才需要重启,进行等待。但是,重启后的读操作可能继续落入其他写操作的置信区间,引发多次重启。所以,读等待的缺点是等待时间可能比较长。
小结
- 时间误差是客观存在的,任何系统都不能获得准确的绝对时间,只能得到一个时间区间,差别仅在于有些系统承认这点,而有些系统不承认。
- 有两种方式消除时间误差的影响,分别是写等待和读等待。写等待影响范围大,所有包含写操作的事务都要至少等待一个误差周期。读等待的影响范围小,只有当读操作时间戳与访问数据项的提交时间戳落入不确定时间窗口后才会触发,但读等待的周期可能更长,可能是数个误差周期。
- 写等待适用于误差很小的系统,Spanner 能够将时间误差控制在 7 毫秒以内,所以有条件使用该方式。读等待适用于误差更大的系统,CockroachDB 对误差的预期达到 250 毫秒。
加餐:读等待和写等待都是通过等待的方式,度过不确定的时间误差,从而给出确定性的读写顺序,但性能会明显下降。那么在什么情况下,不用『等待』也能达到线性一致性或因果一致性?
这个问题可以有两个解决方法:
- 如果分布式数据库使用了 TSO,保证全局时钟的单向递增,那么就不再需要等待了,因为在事件发生时已经按照全序排列并进行了记录。
- 就时间的话题做下延展。『等待』是为了让事件先后关系明确,消除模糊的边界,但这个思路还是站在上帝视角。
根据 Lamport 的论文 "Time, Clocks, and the Ordering of Events in a Distributed System"。
假设两个事件发生地的距离除以光速得到一个时间 X,两个事件的时间戳间隔是 Y,时钟误差是 Z。如果 X>Y+Z,那么可以确定两个事件是并行发生的,事件 2 就不用读等待了。这是因为既然事件是并行的,事件 2 看不到事件 1 的结果也就是正常的了。
学习资料
Leslie Lamport: Time, Clocks, and the Ordering of Events in a Distributed System
更新时间:2022-02-07 13:36:23
本文由 caroly 创作,如果您觉得本文不错,请随意赞赏
采用 知识共享署名4.0 国际许可协议进行许可
本站文章除注明转载 / 出处外,均为本站原创或翻译,转载前请务必署名
原文链接:https://caroly.fun/archives/分布式数据库四
最后更新:2022-02-07 13:36:23

